the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 28 Aug 2024
| 28 Aug 2024
Technical note: Posterior uncertainty estimation via a Monte Carlo procedure specialized for 4D-Var data assimilation
Mikael Kuusela
Brendan Byrne
Junjie Liu
Through the Bayesian lens of four-dimensional variational (4D-Var) data assimilation, uncertainty in model parameters is traditionally quantified through the posterior covariance matrix. However, in modern settings involving high-dimensional and computationally expensive forward models, posterior covariance knowledge must be relaxed to deterministic or stochastic approximations. In the carbon flux inversion literature, (Chevallier et al., 2007) proposed a stochastic method capable of approximating posterior variances of linear functionals of the model parameters that is particularly well suited for large-scale Earth-system 4D-Var data assimilation tasks. This note formalizes this algorithm and clarifies its properties. We provide a formal statement of the algorithm, demonstrate why it converges to the desired posterior variance quantity of interest, and provide additional uncertainty quantification allowing incorporation of the Monte Carlo sampling uncertainty into the method's Bayesian credible intervals. The methodology is demonstrated using toy simulations and a realistic carbon flux inversion observing system simulation experiment.
- Article
(1015 KB) - Full-text XML
- BibTeX
- EndNote





Uncertainty quantification (UQ) for data assimilation (DA) tasks is often non-trivial but scientifically paramount to their understanding and interpretation. Since DA broadly describes methods combining observations with a computational model of a physical system, a Bayesian framework is often sensible for inference for the model parameters, as the posterior distribution quantifies knowledge resulting from this combination. As such, Bayesian statistical models are regularly used as the UQ framework. For example, Bayesian procedures play a central role in the general idea of optimal estimation (Rodgers, 2000), the broad field of DA (Kalnay, 2003), and the more specific field of carbon flux estimation (Deng et al., 2014; Liu et al., 2016). Inference for DA tasks using this statistical framework is typically challenging due to high-dimensional settings (e.g., high-resolution spatiotemporal grids) and the computer model's implicit numerical definition of the physical system of interest, often requiring supercomputers and long compute times to run the relevant forward model. Prior and observation error distributions are often assumed to be Gaussian, yielding a Gaussian posterior distribution under a linear forward model. Although a Gaussian posterior distribution can be exactly characterized by its mean vector and covariance matrix, the high dimensionality makes dealing directly with the posterior covariance matrix intractable and the implicit computationally demanding forward model makes standard traditional Bayesian computational techniques, such as Markov chain Monte Carlo (MCMC), infeasible. The implicit posterior necessitates the development of computational methods that implicitly access it.
The challenge of high-dimensional DA can be confronted using a variational approach such as four-dimensional variational (4D-Var) data assimilation (Kalnay, 2003) (mathematically equivalent to optimal estimation as detailed in Rodgers, 2000), which aims to find an optimal model parameter vector via numerical optimization rather than sampling from a Markov chain. The 4D-Var approach is the DA focus of this technical note. The optimal model parameter vector minimizes a cost function balancing model error with observations and proximity to prior information about the unknown state. When the forward model can be run in adjoint mode to obtain the cost function gradient, the optimal state can be iteratively solved using a first-order optimization method.
CO2 flux inversion is a representative example of a high-dimensional DA task to which Bayesian modeling is applied, and 4D-Var is used to compute estimated flux fields (Crowell et al., 2019; Enting et al., 1995; Gurney et al., 2002). In this problem, estimates of net surface–atmosphere CO2 fluxes are inferred from atmospheric CO2 measurements, with fluxes and atmospheric measurements being related by a chemical transport model (the computational forward model). However, the relatively sparse atmospheric CO2 observations underconstrain surface fluxes of CO2, and regularization with prior information is the Bayesian approach to making the problem well-posed. These analyses have historically assimilated measurements of atmospheric CO2 from a global network of flask and in situ measurements (Enting et al., 1995), but more recent work (Byrne et al., 2023; Crowell et al., 2019; Deng et al., 2014; Houweling et al., 2015) has shifted to assimilating space-based column-averaged dry-air mole fractions, denoted , as observation availability has expanded since 2009. In these analyses, the prior and error distributions are typically assumed to be Gaussian and the forward model can be reasonably assumed to be linear in the net surface–atmosphere fluxes.
When the number of model parameters is low and a forward model run is inexpensive, it is possible to explicitly construct the posterior covariance matrix. Successful examples of this approach date back to at least Vasco et al. (1993) in seismic tomography, where inversion was performed on 12 496 model parameters. However, more contemporary problems typically have orders of magnitude more parameters and substantially more expensive forward models, requiring other approaches to access posterior covariance matrix information. Once the discretization of the computational model is set, the dimensionality problem can be handled either by defining an approximate statistical model on a lower-dimensional problem or by working in some subspace of the full-dimensional problem. A recent example of the first strategy is seen in Zammit-Mangion et al. (2022) in the WOMBAT inversion system, which lowers the dimension of the statistical model via an intelligently chosen set of basis functions, facilitating MCMC. Alternatively, Petra et al. (2014) propose, with stochastic Newton MCMC (SN-MCMC), the potential for MCMC in the full parameter space using a low-rank approximation of the posterior covariance within the proposal distribution of a Metropolis–Hasting algorithm. Although WOMBAT and SN-MCMC are both MCMC-based, WOMBAT assumes a linear forward model, while SN-MCMC does not, allowing it to characterize non-Gaussian posteriors. Staying with a linear forward model assumption, other approaches leverage low-rank posterior covariance approximations. Flath et al. (2011) developed a low-rank algorithm for approximating the posterior covariance by computing the leading eigenvalues and eigenvectors of a prior-conditioned Hessian matrix of the associated objective function (i.e., the log posterior). In a similar spirit, Kalmikov and Heimbach (2014) provided a derivative-based algorithm to compute leading Hessian eigenvalues and eigenvectors and extend the uncertainty quantification to quantities of interest in global ocean state estimation. The algorithms in both Flath et al. (2011) and Kalmikov and Heimbach (2014) rely upon the Lanczos method (Lanczos, 1950) for matrix-free computation of the low-rank approximation. Alternatively, Bousserez and Henze (2018) more recently proposed a low-rank approximation algorithm dependent upon the randomized singular value decomposition (SVD) algorithm (Halko et al., 2011). All of the aforementioned methods can be grouped by their reliance upon some low-dimensional deterministic approximation.
In contrast, stochastic approximations of the posterior distribution rely upon neither pre-inversion dimension reductions nor low-rank matrix approximations but rather generate ensembles of inversions using random generators. These approaches usually share fundamental model (e.g., linearity of the forward model in the model parameters) and observation error (e.g., Gaussian errors) assumptions. Although approaches like particle filtering allow for relaxation of these assumptions, they have mostly been successful for relatively low-dimensional problems and are in a nascent stage of applications to high-dimensional DA tasks (Doucet et al., 2000; Potthast et al., 2018; Maclean and Vleck, 2021). As such, there is still a great need for UQ methods for high-dimensional DA approaches relying upon those common assumptions. In carbon flux inversion, Chevallier et al. (2007) developed such a method to estimate the posterior variance of functionals of the flux field (i.e., maps from the flux field to the reals). The method uses the forward model, specified prior, and known observation error distributions in a particularly efficient manner. Broadly, the algorithm creates an ensemble of prior means and observation errors, sampling according to their respective distributions. For each ensemble member, it finds the maximum a posteriori (MAP) estimator, to which the functional is applied. Finally, it finds the empirical variance across the ensemble members to estimate the posterior variance of the functional. This method is well-suited for carbon flux estimation and 4D-Var-based DA UQ more generally for a few key reasons. First, each ensemble member is computationally independent, making the method parallelizable and hence offering a substantial computational benefit compared to sequential methods, such as MCMC. Second, although in general prior misspecification biases the posterior, the prior mean does not need to be correctly specified in order for the procedure to produce an unbiased estimator of the posterior variance. Third, the ensemble of inversions can flexibly produce UQ estimates for arbitrary functionals post hoc, as opposed to requiring the specification of a functional ahead of the analysis. Finally, since this method is more generally a Monte Carlo (MC) method for a Gaussian statistical model, the method's sampling uncertainty can be analytically characterized and accounted for in the final UQ estimate. The ability to easily characterize this uncertainty in the uncertainty stands in contrast to the difficulty in characterizing deterministic error in the aforementioned low-dimensional approaches.
Although Chevallier et al. (2007) appear to have been the first to develop this method, which was later applied in Liu et al. (2016), we are unaware of a formal statement or analysis of this algorithm. These previous works also did not quantify the algorithm's MC uncertainty. As such, the primary contributions of this paper are a rigorous formal statement of the algorithm, an analysis showing the convergence of its output to the true posterior quantity of interest, and uncertainty quantification of the algorithm itself so that the algorithm's sampling uncertainty can be accounted for in the final inference. Since this algorithm originated in the carbon flux inversion literature, we use carbon flux inversion as a running application example throughout this technical report. However, the approach is applicable to any 4D-Var DA implementation subject to the mathematical assumptions and considerations outlined in Sect. 2.
The rest of this paper is structured as follows. In Sect. 2, we fully describe the algorithm, present mathematical results proving its correctness, and derive deflation and inflation factors to apply to the estimated posterior uncertainty to quantify the MC uncertainty. Proofs of the mathematical results can be found in Appendix A. In Sect. 3, we provide two experimental demonstrations: the first is a low-dimensional problem in which we explicitly know the linear forward model and the second is a carbon flux observing system simulation experiment (OSSE) to which we applied this method to compute credible global monthly flux intervals along with their MC uncertainty. Finally, we provide some concluding remarks in Sect. 4. For reference, all mathematical notation in order of appearance is collected in Table 1.
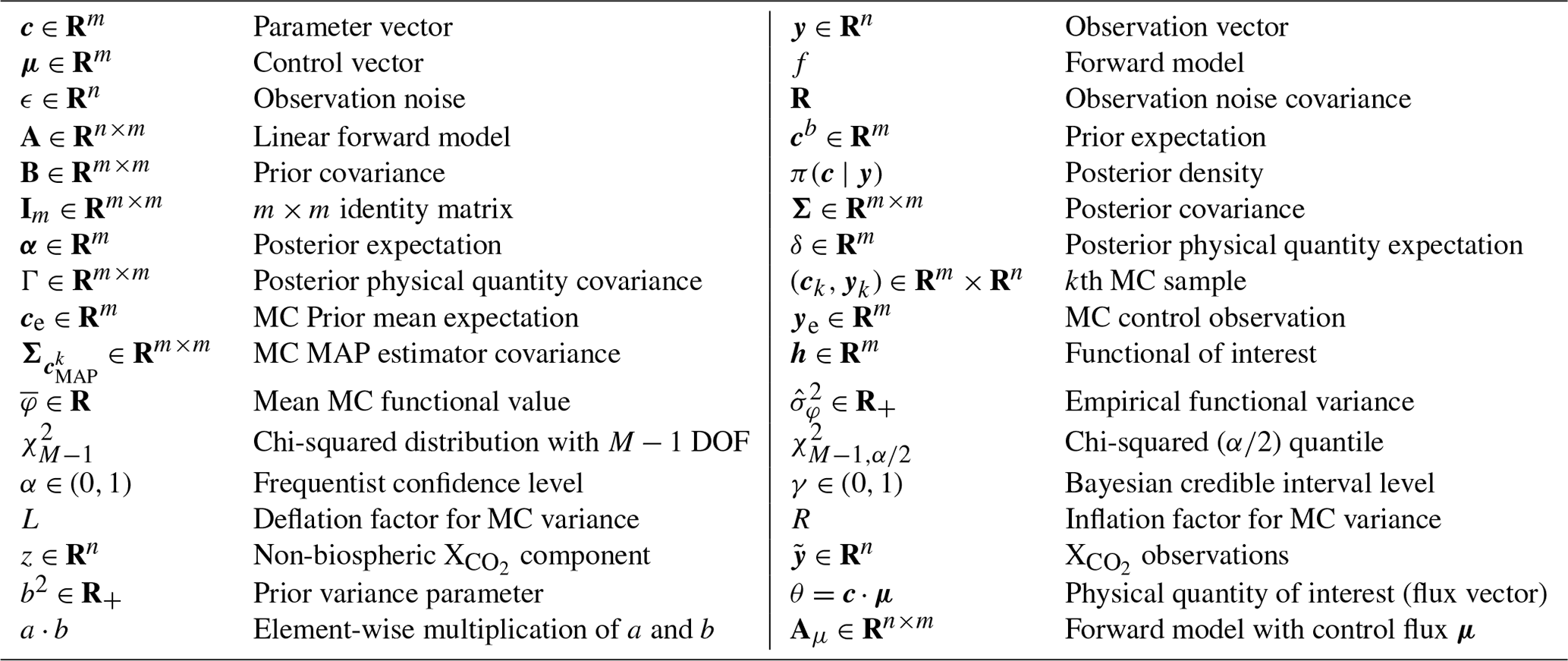
Table 1Mathematical symbols and notation used herein (roughly in order of appearance).
2.1 The Bayesian 4D-Var setup
The following equation describes the relationship between a parameter vector, c∈Rm, that we wish to optimize and an observation vector, y∈Rn:
where is the forward model mapping from parameter space to observation space, μ∈Rp is a control vector of parameters that remain fixed during the optimization, and is the observation covariance matrix. To streamline notation, we denote henceforth the forward model using only the parameter vector as input, i.e., f(c). To regularize the problem and provide uncertainty quantification of the estimated parameter vector, c in Eq. (1) is given a Gaussian prior distribution, yielding the following Bayesian generative model:
where cb∈Rm is the prior mean and B is the prior covariance matrix. Finding the mode of the posterior c∣y defined by Eqs. (2) and (3) is the objective of 4D-Var data assimilation, a method simultaneously optimizing the parameter vector over all time steps, which has been applied to a wide range of applications in Earth sciences (Deng et al., 2014; Kalmikov and Heimbach, 2014; Liu et al., 2016). The 4D-Var method can be regarded as a least-squares optimization with an ℓ2 regularizer (ridge regression), or, equivalently, as maximum a posteriori (MAP) estimation in the Bayesian paradigm. This connection means that the 4D-Var optimization is connected to the posterior resulting from the prior and likelihood in Eqs. (2) and (3). From the Bayesian perspective, the 4D-Var cost function F(c) is the negative log-posterior density of the scaling factors given the observations:
where C∈R is a normalizing constant for the posterior distribution and π(c∣y) denotes the posterior density. Thus, finding the MAP estimator, i.e., the c that maximizes the posterior density, is equivalent to finding the vector c that minimizes the 4D-Var cost function. As such, uncertainty quantification can be handled through the covariance matrix of the posterior, which we denote as .
To facilitate exposition, we assume the forward model is linear, i.e., f(c)=Ac, though we address strategies to apply the Monte Carlo procedure described in Sect. 2.2 to nonlinear forward models in Sect. 2.2.1. As such, we assume the linear Bayesian model,
on which the primary analysis of this technical note is performed. Not only is the linearity assumption helpful to expose the validity of the Monte Carlo algorithm under consideration, but it is also valid in carbon flux inversion, our primary application of interest. We discuss the necessary adjustments to apply this approach to carbon flux inversion in Sect. 3.2. Assuming linearity, Gaussian prior, and Gaussian likelihood ensures the equivalence between the posterior mode and expectation, and hence optimizing Eq. (4) is equivalent to obtaining the posterior expectation. We emphasize that the matrix A is not explicitly available to us but is instead implicitly defined by a computational model. Thus, even though the linear assumption allows explicit analytical interpretation, we are not able to interact with the matrix in arbitrary ways in practice.
Assuming linearity of the forward model, the posterior mean (mode) and covariance of c are analytically tractable. Hence, , where, by Eqs. 4.3 and 4.7 in Rodgers (2000), the posterior mean and covariance equations, we have
Note that α is also the MAP estimator of c. Since the forward model A is only known implicitly via a computer simulator, making direct use of Eqs. (7) and (8) is numerically intractable. Instead, the 4D-Var cost function in Eq. (4) is typically minimized using the L-BFGS-B algorithm (Byrd et al., 1995) with the cost function gradient computed numerically using the adjoint of f (Henze et al., 2007). L-BFGS-B can often find a reasonable approximation of the posterior mean and mode α in a handful of iterations. We now describe the Monte Carlo method, which provides an approach for uncertainty quantification of α despite the analytical intractability of the posterior covariance Σ.
2.2 The Monte Carlo procedure
To execute the Monte Carlo procedure introduced in Chevallier et al. (2007), we generate M ensemble members. For each , we sample a new prior mean ck independently and identically distributed (i.i.d.) and new observation yk i.i.d. as follows:
where ce is a chosen prior expectation to perturb and ye∈Rn is a chosen control observation to perturb. Chevallier et al. (2007) operated in a simulation setting where they knew the true parameter, which we call cclim following their notation. As such, they set ce=cclim and ye=Acclim. When using real data, cclim is not known, and so it is sensible to set this expectation using a physically reasonable value (for example, see Sect. 3.2 for how to set these expectations in more recent carbon flux inversion settings). However, as we show below, the choice of the expectations in Eqs. (9) and (10) does not particularly matter under the linear Gaussian assumption (see Eq. 12), as long as . Therefore, each Monte Carlo iteration involves sampling a pair according to Eqs. (9) and (10).
The MAP estimator from Eq. (8) corresponding to prior mean ck and observation yk is analytically tractable for each ensemble member when A is explicitly known:
Since is a linear function of two Gaussian random variables, it is also Gaussian. Therefore, linear combinations of it are also Gaussian, which will be a useful fact in the analysis performed in Sect. 2.3. The covariance matrix of this MAP estimator, henceforth denoted as , is
where the covariance decomposition in line two follows from and the final equality follows from . Thus, the covariance matrix of the Monte Carlo ensemble MAP estimators is equal to the desired posterior covariance Σ. We also note that using the expectation choices from Chevallier et al. (2007) of ce=cclim and ye=Acclim means that .
The above covariance equality is the key fact allowing this method to work, as it allows us to compute an empirical estimate of the posterior covariance by sampling from two unconditional distributions and solving the 4D-Var objective. To the best of our knowledge, proof of this equality has not appeared in previous literature on this method. However, there is a similar method used in the spatial statistics literature to sample from conditional random fields as shown in Chap. 3, Sect. 3.6.2, of Cressie (1993) and Chap. 7, Sect. 7.3.1, of Chiles and Delfiner (2012). As described in Chiles and Delfiner (2012), this sampling method is able to sample from complex conditional random fields if one can sample from unconditional distributions with the appropriate distributions. This requirement more broadly matches the covariance equality requirement of this Monte Carlo procedure and suggests a potential connection between these two sampling procedures.
Since the linear forward model is not explicitly available in most 4D-Var scenarios, each ensemble member MAP estimator must be obtained with an iterative optimization algorithm minimizing Eq. (4) with ck and yk as the prior mean and observation vectors. Once these ensemble members are obtained, we could in principle estimate the posterior covariance matrix Σ with the empirical covariance estimator based on the Monte Carlo ensemble as follows:
where . However, in practice, most data assimilation applications, like carbon flux inversion, are high dimensional, making direct interaction with these covariance matrices difficult. Indeed, accurate estimation of Σ using Eq. (13) would require an enormously large Monte Carlo ensemble and would require storing and working with an m×m matrix, where m∼105 or larger. Fortunately, we often care about the variance of one-dimensional summaries of c, such as the posterior variance of some linear combination of c, as opposed to the full posterior covariance matrix. For instance, we might wish to estimate North American carbon fluxes over a particular month.
Obtaining quantities of the above type is mathematically implemented using a linear functional of the underlying high-dimensional parameter. That is, we wish to characterize the posterior of , where h∈Rm contains weights necessary to aggregate the desired vector components. Hence, building off Eqs. (7) and (8), we obtain the posterior distribution for the functional of interest:
We wish to obtain the posterior variance of this functional. Define . We could inefficiently estimate this using , but we wish to avoid working directly with the full empirical covariance matrix. The following algebraic steps provide a better alternative:
where and . The above algebra shows that the posterior variance of the functional can be computed using the functionals of the Monte Carlo samples without having to form the full empirical covariance matrix. See Algorithm 1 for a succinct exposition of the above procedure. Notice that the functional does not need to be specified when creating the Monte Carlo ensemble. As long as the ensemble is stored and made available to the end users, they may evaluate post hoc the uncertainty in any functional that is of interest in their specific use case.
Algorithm 1Monte Carlo algorithm to estimate posterior uncertainty in 4D-Var data assimilation
Inputs
-
M∈ℕ: number of Monte Carlo samples
-
: observation error covariance built from observation uncertainties
-
B∈Rm: parameter prior variance
-
: forward model mapping from parameter to observations space (note, this can be known either explicitly via a matrix or implicitly via a computer simulator)
-
ce∈Rm: prior expectation
-
ye∈Rn: control observation
-
h∈Rm: vector defining the functional of interest
Steps
-
Let 𝒮 denote an array of length M that will store the MAP estimators for each Monte Carlo sample.
-
For ,
-
Estimate posterior functional variance:
-
Compute the mean Monte Carlo sample functional, , where .
-
Compute the empirical posterior functional variance,
-
2.2.1 Considerations for when f is nonlinear and other critical assumptions
Our demonstration of this procedure's validity relies on several assumptions which we restate here to clarify and comment on the procedure's resilience to their violation. For the primary applications of interest where the forward model is not analytically tractable, this approach's feasibility relies upon efficient computation of the posterior expectation. Furthermore, proving this algorithm's validity relies upon the equivalence between the posterior covariance and the covariance of the ensemble members. We showed this equivalence by appealing to equations following from the linear forward model and Gaussian error assumptions. Since relaxing the Gaussian assumption would completely change the 4D-Var objective function and this technical note is primarily about standard 4D-Var, we do not consider this relaxation. However, linearity is not necessary to use 4D-Var, which is one of the benefits of using such a variational approach. Although it is possible that covariance equivalence holds for nonlinear forward models, the linearity assumption is necessary in our demonstration, since we require the equivalence between the posterior expectation and MAP to show the covariance of the ensemble element.
There are at least two options for posterior covariance-based uncertainty quantification under a nonlinear forward model based on linearizing the forward model around a particular point in the parameter space. Linearizing the forward model around a point x0 takes the form
where is the Jacobian of the forward model about c0 and effectively becomes the linear forward model under linearization. Following the terminology of Rodgers (2000), linearization is applicable for “nearly linear” and “moderately nonlinear” problems. Nearly linear problems are those for which “linearization about some prior state is adequate to find a solution” (Rodgers, 2000). In this circumstance, one can linearize the forward model around a prior guess, c0, and proceed with 4D-Var and the Monte Carlo uncertainty quantification procedure as if the forward model is linear as described above. Moderately nonlinear problems are those “where linearization is adequate for the error analysis, but not for finding a solution” (Rodgers, 2000). As such, one can numerically obtain a solution, , to the 4D-Var objective including the nonlinear forward model followed by a linearization around . One can then perform the Monte Carlo procedure with the forward model linearized about the solution to the 4D-Var objective.
2.3 Quantifying the Monte Carlo uncertainty
Although Sect. 2.2 establishes the equality between the Monte Carlo MAP estimator ensemble member covariance and the posterior covariance (and therefore between the equality of the Monte Carlo ensemble member functional variance and the posterior functional variance), we have not yet established that the empirical covariance matrix (and functional variance) converges in terms of probability to the true posterior covariance matrix (and functional variance). There are consistency results showing the empirical covariance matrix converging in terms of probability to the true covariance matrix (see, for instance, Chap. 6 in Wainwright, 2019). However, since this application is primarily concerned with linear functionals of the form as described in Sect. 2.2, we can appeal directly to the consistency of the sample variance as shown, for example, in Chap. 5 in Casella and Berger (2002).
Additionally, using the above algorithm, we would like to know either the uncertainty in the variance estimate given the number of Monte Carlo samples or the number of samples required to obtain a particular level of Monte Carlo uncertainty in the variance. In essence, we would like to quantify the uncertainty in our uncertainty. To do so, we take a frequentist approach and construct confidence intervals on . The confidence intervals can be constructed by recognizing that the ratio of the Monte Carlo functional empirical posterior variance to the true functional posterior variance scaled by (M−1) follows a distribution.
Since is Gaussian, the random variables ( are sampled independently and identically from a Gaussian distribution with some mean and variance . By Theorem 5.3.1 of Casella and Berger (2002), we have the following distributional result:
Thus, for , the distribution in Eq. (20) enables the creation of a 1−α confidence interval for the true posterior variance, , as a function of the empirical posterior variance, . Using the exact distribution in Eq. (20), we can create either one- or two-sided confidence intervals. Focusing on the two-sided case, we have
where is the quantile of a chi-squared distribution with M−1 degrees of freedom. Hence, with some algebraic manipulation we arrive at the confidence interval of the posterior variance,
Since in practice we would like to characterize uncertainty in the same units as the flux estimate, we can provide an analogous confidence interval for the posterior standard deviation by taking square roots of all the terms within the probability statement in Eq. (22), giving
Equation (23) facilitates the computation of a % frequentist interval estimator of the Bayesian credible interval for the functional of interest φ. For each endpoint of the true Bayesian credible interval, we find a confidence interval such that the probability that both endpoint confidence intervals simultaneously cover the true credible interval endpoints is 1−α. Let and be the functional MAP estimator as described in Sect. 2.1. Because the posterior is Gaussian and φMAP is a linear functional, it is a one-dimensional Gaussian random variable. Hence, the Bayesian % credible interval is computed as follows:
where is the quantile of a standard Gaussian distribution. Equation (23) allows us to construct the aforementioned endpoint confidence intervals as follows. For readability, define and . Thus, we have the following,
More concisely, defining
it follows that
The intervals and quantify uncertainty in uncertainty and provide a rigorous probabilistic characterization of the Monte Carlo procedure's uncertainty.
In practice, the original Bayesian credible interval in Eq. (24) can be modified to account for the Monte Carlo uncertainty. To obtain an upper bound on the Bayesian credible interval, we apply an inflation factor (defined above as R) and thus obtain the interval such that . This probability is instead of (1−α), since the probability in Eq. (21) evaluated with only the lower bound yields a probability of . Following the same steps as above, we obtain lower and upper bounds on the lower and upper endpoints of the credible interval of Eq. (24), respectively, holding with probability of exactly . Similarly, to obtain a lower bound on the Bayesian credible interval, we apply a deflation factor (defined above as L) and thus obtain the interval such that , holding with equality by the same logic as that used for the inflation factor.
Observing that the aforementioned inflation and deflation factors monotonically approach 1 as the number of Monte Carlo samples M gets large, the effect of the Monte Carlo procedure wanes as the number of samples grows. As shown in Table 2, the deflation factor monotonically approaches 1 from below as M gets large while the inflation factor monotonically approaches 1 from above as M gets large. As is characteristic of DA methods, each Monte Carlo iteration requires a non-trivial amount of computation, which practically restricts the number of Monte Carlo samples that can be obtained. As such, the inflated interval protects against underestimating the uncertainty, while the deflated interval provides a lower bound or “best-case” scenario for the uncertainty in the Bayesian procedure.
Table 2Inflation and deflation factors for Monte Carlo (MC) estimated posterior standard deviation with α=0.05. When M=100, by inflating the MC-estimated posterior standard deviation by a factor of 1.1607 (inflating by 16.07 %), the extra uncertainty resulting from the MC procedure is accounted for with 97.5 % confidence. Similarly, when M=100, deflating the MC-estimated posterior standard deviation by a factor of 0.8785 provides a lower bound on the true underlying Bayesian uncertainty with 97.5 % confidence. When considered simultaneously, the inflation and deflation factors bracket the true uncertainty with 95 % confidence.

3.1 Low-dimensional example
We construct a two-dimensional example to provide a numerical demonstration that this MC procedure computes a consistent estimate of the posterior covariance and is numerically close in practice. Define a linear forward model by
where ϵ>0. Let ctrue∈R2 be the true value of some physical parameter, and suppose we set up Eqs. (5) and (6) as
We use the values in Table 3 to demonstrate the covariance agreement between the analytical equations for the posterior and the Monte Carlo ensemble member in addition to showing their agreement with the empirical covariance computed from the Monte Carlo ensemble members. We also provide an empirical demonstration that the empirical covariance matrix converges to the posterior covariance in the Frobenius norm as the number of ensemble elements M gets large.

Using the settings in Table 3, we obtain the following posterior covariance matrix by Eq. (7):
For the analytical covariance of the MAP estimator, we obtain the following matrix using Eq. (12):
Indeed, these matrices are expected to be the same. Using simulated ensemble members, we obtain the following empirical covariance matrix using Eq. (13):
This empirical covariance matrix is qualitatively close to the analytical matrices, even for only M=102. To show how the empirical covariance computed from the Monte Carlo ensemble elements converges to the true posterior covariance, we repeat the above implementation of the Monte Carlo procedure for . For each M value, we compute the Frobenius norm of the difference between the true posterior covariance and the empirical covariance to measure the estimation error, i.e., . Since this estimation error is itself random, for each setting of M, we sample 100 realizations of the Monte Carlo procedure to obtain a mean norm difference. The results of this procedure are presented in Fig. 1 and show that the estimation error exponentially decreases as the ensemble size gets large. By regressing on log 10M, we estimate the error convergence rate to be CM−0.49, where C≈100.22, as shown by the fitted line in Fig. 1.
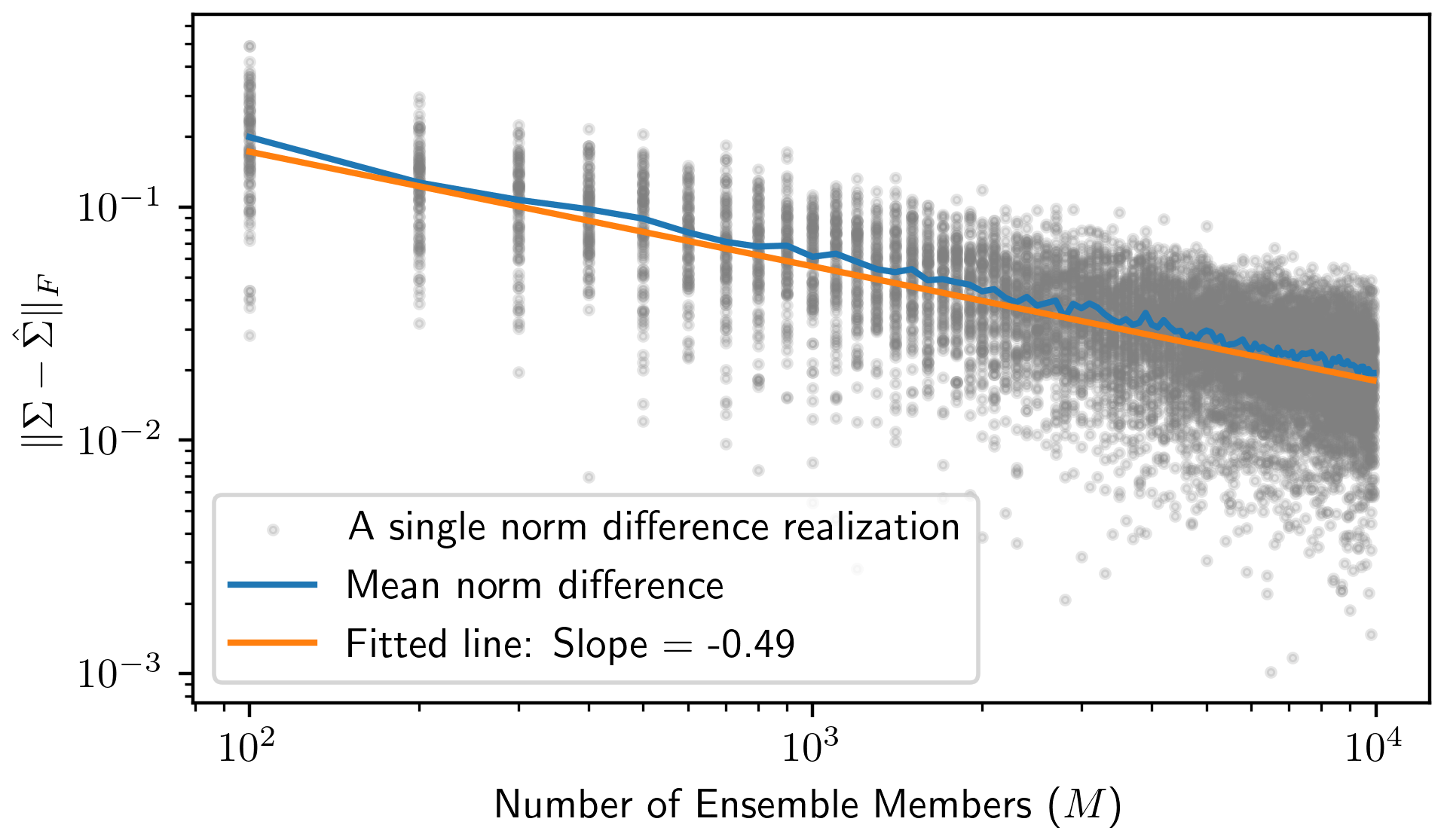
Figure 1The Monte Carlo procedure is implemented on the low-dimensional example for a variety of ensemble sizes () to show that the empirical covariance resulting from the Monte Carlo procedure quickly gets close, in terms of the Frobenius norm, to the posterior covariance as the number of ensemble members gets large. For each ensemble size M, we sample 100 realizations of the Monte Carlo procedure (shown in the gray dots) and find the average over these 100 realizations to see the expected behavior at each ensemble size. The orange regression line results from regressing on log 10M, where the slope estimates the exponential error convergence rate.
3.2 Carbon flux inversion OSSE
We show an example of this Monte Carlo procedure being used to compute posterior uncertainties for global carbon fluxes along with the adjusted uncertainties from Sect. 2.3. We first detail adjustments to the 4D-Var setup and the Monte Carlo procedure for carbon flux inversion, followed by the particulars of our simulation study and the Monte Carlo procedure results.
3.2.1 Applying 4D-Var and the Monte Carlo procedure to carbon flux inversion
Following along with the mathematical setup of Henze et al. (2007), the prior and posterior distributions are defined in a scaling-factor space, and hence the prior and posterior distributions of the physical quantity of interest are obtained by multiplying each respective scaling factor by a control quantity. In carbon flux estimation, the control quantity is a control flux, typically an ansatz CO2 flux between the Earth's surface and the atmosphere. Note that if the prior distribution mean in scaling-factor space is unity, then the control flux is also the prior mean in the physical quantity of interest space. Mathematically, let c∈Rm denote a scaling-factor vector; be the observation vector; μ∈Rm be the control physical quantity; and be the physical quantity implied by c and μ, where ⋅ denotes element-wise multiplication. We substitute these elements into the original mathematical model stated in Eq. (1). The observation vector is a sequence of X observations produced by a remote sensing satellite, e.g., GOSAT or OCO-2 (O'Dell et al., 2012). The forward model, f, is a composition of an atmospheric transport model mapping scaling factors to atmospheric CO2 concentrations with a remote sensing observation operator mapping CO2 concentrations to X scalar values. The atmospheric transport model is known to be affine in its scaling factors due to the physics of CO2 atmospheric transport. The exact mapping from atmospheric CO2 concentrations to X is nonlinear, but in line with Liu et al. (2016), we use an affine approximation involving the known GOSAT averaging kernel. As such, the affine composed function f is of the form , where is the linear forward model matrix, c⋅μ denotes the component-wise multiplication of μ by the scaling factors c, and z is comprised of the non-biospheric CO2 contribution to the observations along with the prior mean of the X retrieval algorithm. As such, we define , giving the linear model
to which the previous analysis can nearly be applied. These definitions lead to the following Bayesian generative model:
where cb∈Rm is the scaling factor prior mean and B is the prior covariance matrix.
In this study, the prior covariance B is parameterized with a single real value, B:=b2Im, where . This is in line with several published studies (Deng et al., 2014; Liu et al., 2016) and implies that all prior spatiotemporal indices are statistically independent. Similarly, the noise covariance R is assumed to be a diagonal matrix where each diagonal element is simply the variance of the corresponding X observation. As such, each diagonal element depends on the uncertainty in its corresponding X retrieval, and the observations are assumed statistically independent given the scaling factors.
The uncertainty quantification objective is then to find the posterior uncertainty in a linear functional, defined by vector h∈Rm, of the physical quantity, , given the observations. As shown in Algorithm 1, we can obtain an estimate of this uncertainty without computing the entire posterior covariance matrix as long as the covariance of the Monte Carlo ensemble elements is equal to the posterior covariance. We show this equivalence in the following argument.
For ease of notation, we rewrite Eq. (36) using a shorthand notation for the ⋅ operation (see Appendix A), i.e., , so that
Hence, applying Eqs. (7) and (8) and accounting for the control flux we have
where Eq. (38) follows from Corollary 4 and Eq. (39) follows from Lemma 5 in Appendix A. These covariance and expectation equations define the Gaussian posterior for c. The posterior distribution for the physical quantity, , is , where
and we have used Lemmas 1 and 2 from Appendix A.
The argument used in Eq. (12) to establish the equivalence between the posterior covariance and the Monte Carlo ensemble element covariance also holds under the scaling-factor and control flux setup in carbon flux inversion. One simply needs to apply the lemmas in the Appendix to account for the component-wise relationship between the scaling factors and the control flux to establish covariance equality in the scaling-factor space. This equality further extends to the physical quantity space, i.e., carbon flux space. The estimator of the physical quantity corresponding to is
Using the result from Lemma 2 in Appendix A, the covariance matrix Cov[θk] of this estimator is
Hence, the covariance matrix of the Monte Carlo physical quantity ensemble element is equal to the posterior covariance matrix of that physical quantity. Because of this equality, the empirical variance of the functional ensemble can be used to estimate the posterior variance of the functional of interest defined by h, as shown in Step 3 of Algorithm 1. Note that because the validity of Algorithm 1 is based upon the covariance equivalence and not the functional of interest, once a Monte Carlo ensemble has been obtained, one can obtain posterior uncertainties for any collection of desired functionals without having to generate a new Monte Carlo ensemble. This feature is particularly appealing in an application like carbon flux inversion, since scientists are usually interested in estimating posterior uncertainties for many regions (each of which can be encoded by a functional), which would be computationally cumbersome if each functional required a new Monte Carlo ensemble. It also enables the obtaining of uncertainties in new functionals that become the subject of scientific interest only after the generation of the Monte Carlo ensemble.
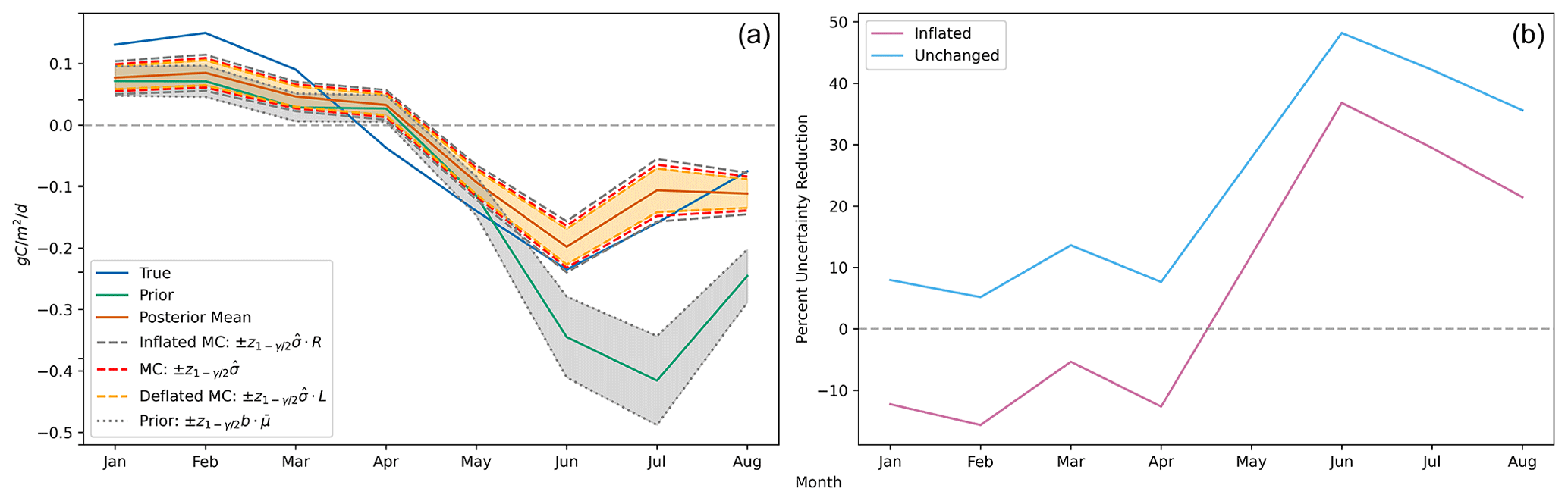
Figure 2(a) Estimated posterior credible intervals around the monthly global flux functionals show markedly improved uncertainty over the prior during boreal summer months. The three interval types shown are the unchanged MC-estimated intervals (red), the inflated MC-estimated intervals (gray), and the deflated MC-estimated intervals (orange). As described in Sect. 2.3, for each month, the true upper and lower credible interval endpoints are contained within the inflated and deflated endpoints with probability . Note that is a shorthand notation for the empirical functional standard deviation as defined in Step 3 of Algorithm 1; is the globally averaged control flux to which the prior uncertainty, b, is applied for each month; and R and L are the inflation and deflation factors, respectively, as defined in Table 2. We observe that with even as few as M=60 ensemble members, at the monthly/global scale, the magnitude of the Monte Carlo sampling uncertainty is small in comparison to the posterior uncertainty. (b) The percent reduction in uncertainty from prior to posterior for the monthly global fluxes is most significant during the boreal summer. The light-blue curve shows the percent reduction estimated with the unchanged MC-estimated posterior standard deviation, while the magenta curve shows the percent reduction estimated with the inflated MC-estimated posterior standard deviation. The true reduction is larger than the reduction shown by the latter curve with 97.5 % confidence.
3.2.2 OSSE setup and Monte Carlo procedure results
We follow the flux inversion setup used by Byrne et al. (2019) (see Sect. 2.3 of that study). This setup uses the GEOS-Chem Adjoint model (Henze et al., 2007) to estimate scaling factors on a 4°×5° surface grid from January 2010 up to and including August. For each spatial point, there is one scaling-factor parameter for each month, totaling scaling-factor parameters. This model is linear in terms of realistic fluxes (e.g., not including abnormally large negative fluxes) and hence amenable to this uncertainty quantification procedure. The OSSE defines ground-truth fluxes from the Joint UK Land Environment Simulator (JULES) (Clark et al., 2011; Harper et al., 2018) and uses net ecosystem exchange (NEE) fluxes from NOAA's CarbonTracker version CT2016 (Peters et al., 2007, with updates documented at https://www.esrl.noaa.gov/gmd/ccgg/carbontracker/, last access: 19 August 2024) as the control fluxes. The satellite observations for the assimilation are generated from the JULES fluxes by running a forward GEOS-Chem simulation and sampling the model with the GOSAT observational coverage and observation operator (O'Dell et al., 2012).
The prior uncertainty, as described in Eq. (5), is set to b=1.5 (where B=b2IM). To perform the Monte Carlo procedure, we draw M=60 ensemble members, as described in Sect. 2.2. The observation uncertainty Σ (a diagonal matrix, as the observations are assumed to be independent) comes directly from the GOSAT data product and varies between observations. For each ensemble member k, the output of the GEOS-Chem Adjoint optimization provides monthly scaling-factor MAP estimators according to the ensemble member inputs as described by Eq. (11). Each ensemble MAP estimator is then multiplied by the control flux to obtain a MAP estimator in flux space.
The functionals of interest φ are monthly global fluxes. The flux values on the 3 h 4°×5° spatial–temporal grid are mapped to a global monthly flux using a weighted average with weights proportional to the surface area of each grid cell and uniform time weighting. The global flux posterior variance is computed for each month by finding the empirical variance of the Monte Carlo global flux members, as shown in Eq. (18). To get a sense of how the DA is reducing prior uncertainty, for each month, we compute a percent (%) uncertainty reduction as follows:
Since we obtain an estimate of the posterior standard deviation through the Monte Carlo procedure, we do not precisely know Eq. (44), and thus we consider the reduction in terms of both the raw Monte Carlo point estimate of the posterior standard deviation and its inflated version (i.e., R as defined in Sect. 2.3).
The left side of Fig. 2 shows the time series of global mean functionals and their credible intervals.
The posterior flux is shown to have reduced error against the true flux, especially during the boreal summer months. Similarly, the Monte Carlo posterior uncertainty estimate shows considerable reduction relative to the prior. The uncertainty estimates with inflated endpoints increase the posterior uncertainty by 22 %, while the deflated endpoints decrease the posterior uncertainty by 15 %, resulting in credible interval endpoint bounds that capture the true credible interval endpoints with 95 % probability. The right side of Fig. 2 further emphasizes the prior-to-posterior uncertainty reduction that we mathematically expect. However, we notice that the inflated uncertainty is only reduced during boreal summer months. In January, February, March, and April, the inflated Monte Carlo estimated posterior uncertainty is actually larger than the prior uncertainty. There is a logical explanation for this: since most of the landmass generating NEE fluxes is in the Northern Hemisphere and GOSAT requires sunlight to measure , the satellite observations impose much weaker constraints on the fluxes during boreal winter. Furthermore, since the prior uncertainty is defined as a percentage, the prior is more concentrated during the boreal winter months when the absolute magnitude of the CarbonTracker fluxes is smaller. As a result of these two effects, the actual posterior uncertainty during the winter months is only slightly smaller than the prior uncertainty. Since we obtain a noisy Monte Carlo estimate of this uncertainty from using 60 ensemble members, the inflated value accounting for the Monte Carlo uncertainty in the posterior uncertainty is slightly larger than the prior uncertainty.
For Bayesian uncertainty quantification in which the forward model is only available as a simulator, the carbon flux estimation community has proposed a useful Monte Carlo method to compute posterior uncertainties. This method is especially well suited to DA tasks, since it is parallelizable, works with computationally intensive physical simulators, and allows for flexible post hoc uncertainty quantification on any desired functional of the model parameters. In this technical note, we analytically established the mathematical correctness of this procedure in the case of a linear forward model and Gaussian prior and error distributions and provided additional uncertainty quantification to account for the Monte Carlo sampling variability in the final estimated credible interval. We also provided two numerical examples. In the first, we demonstrated the agreement between the analytical equations and empirical results for an explicitly known linear forward model. In the second, we showed that this procedure applies to a large-scale DA problem in the form of a carbon flux inversion OSSE, and we reasoned that the uncertainty quantification results are mathematically and practically sensible.
Future investigations of this method could be based on an exploration of how many ensemble members must be sampled before the Monte Carlo uncertainty is sufficiently small in comparison to the posterior uncertainty. It is also not immediately clear if this procedure would work with DA algorithms other than 4D-Var and under a relaxation of the Gaussian assumptions as our demonstration relied upon explicitly showing the equivalence between the posterior and ensemble member covariances. As noted in Sect. 2.2, given this algorithm's similarity to the conditional sampling procedure in the spatial statistics literature, there might be ways to relax the linear and Gaussian assumptions so that this algorithm can work in more general DA scenarios. Such an approach would need to demonstrate the covariance equivalence in some way. Finally, the validity of this procedure has been shown for quantifying the uncertainty in the model parameters, but there are also other sources of uncertainty in DA problems, such as uncertainty about the forward model or auxiliary inputs to the forward model. Since these uncertainty sources are typically quantified by looking at ensembles of models or model inputs, perhaps there is a way to use a Monte Carlo procedure like this one to account for such systematic uncertainties as well.
There are a few key properties of the element-wise multiplication operation that must be stated in order to support the derivation of the equations presented in this paper.
For the following, let x∈Rm be a random vector such that 𝔼[x]=μ and Cov[x]=Σ and let xi denote the ith element of x. Additionally, suppose a∈Rm and .
Lemma 1.
The proof is as follows. By definition, we have
Lemma 2.
The proof is as follows. There are two terms that need to be computed: (1) Var[xiai] and (2) Cov[xiai,xjaj]. Term (1) is straightforward by properties of variance; namely, . Term (2) simply requires the definition of covariance; i.e.,
Hence, it follows that .
Lemma 3. Let μ∈Rm and let Aμ be such that the ith row of Aμ is equal to [Aijμj]i. Then the following equation holds:
The proof is as follows. To prove Eq. (A3), first note that . Let i∈[m] and j∈[n]. By definition, we have
Hence, we can see that
and we have the desired result.
Corollary 4. Let be a positive-definite matrix, and let Aμ be defined as in Lemma 3. It follows that
The proof is as follows. Since M is positive-definite, it has a lower triangular Cholesky decomposition, . For all values of i∈[m] and j∈[n], we have the following equivalence:
Therefore, . Thus, Lemma 3 implies
and the result follows, since .
Lemma 5. Let be defined as in the above, , and y∈Rn. Then
The proof is as follows. It is sufficient to show the case when M=In, as otherwise we can simply define a new vector . By matrix multiplication, for all values of j∈[m],
Lemma 6. Let be defined as in the above. Then
The proof is as follows. This property follows simply from the definition of Aμ and matrix multiplication.
Corollary 7. Define as above, let , and let . Then A(a⋅μ) is linear in a.
The proof is as follows. By Lemma 6, we have
GEOS-Chem is publicly available at http://wiki.seas.harvard.edu/geos-chem (Bey et al., 2001), while GEOS-Chem Adjoint requires joining the mailing list and requesting access via a GIT account as detailed here: https://wiki.seas.harvard.edu/geos-chem/index.php/Quick_Start_Guide (Henze et al., 2007). For GEOS-Chem, we use version 8.01.01. The code repository can be found here: https://github.com/geoschem/geos-chem (Bey et al., 2001). For GEOS-Chem Adjoint, we use version v35j.
CarbonTracker data are publicly accessible at https://gml.noaa.gov/ccgg/carbontracker/ (Peters et al., 2007). JULES fluxes were provided by Anna Harper at the University of Exeter. ACOS GOSAT files are publicly available at https://co2.jpl.nasa.gov/ (Jet Propulsion Laboratory, 2019) or https://data2.gosat.nies.go.jp (National Institute for Environmental Studies, 2019).
MS and MK derived all mathematical and statistical results. BB and JL provided scientific expertise. BB provided the OSSE used for the numerical experiment. MS prepared the manuscript and ran all experiments with contributions from all co-authors. All authors participated in reviewing and editing the manuscript.
The contact author has declared that none of the authors has any competing interests.
Publisher’s note: Copernicus Publications remains neutral with regard to jurisdictional claims made in the text, published maps, institutional affiliations, or any other geographical representation in this paper. While Copernicus Publications makes every effort to include appropriate place names, the final responsibility lies with the authors.
We would like to thank Anna Harper for providing the JULES fluxes used in this study's OSSE, the STAMPS research group at Carnegie Mellon University for supporting this work, and the Uncertainty Quantification and Statistical Analysis Group at the Jet Propulsion Laboratory for facilitating this collaboration. We would like to acknowledge high-performance computing support from Cheyenne (https://doi.org/10.5065/D6RX99HX, Computational and Information Systems Laboratory, 2022) provided by NCAR's Computational and Information Systems Laboratory, sponsored by the National Science Foundation.
This research has been supported by the National Science Foundation (grant no. DMS-2053804), the Jet Propulsion Laboratory (grant nos. 1670375, 1689177, and 1704914), the C3.ai Digital Transformation Institute, and the National Aeronautics and Space Administration (grant nos. 80NM0018D004 and 17-OCO2-17-0013).
This paper was edited by Guy Dagan and reviewed by two anonymous referees.
Bey, I., Jacob, D. J., Yantosca, R. M., Logan, J. A., Field, B. D., Fiore, A. M., Li, Q., Liu, H. Y., Mickley, L. J., and Schultz, M. G.: Global modeling of tropospheric chemistry with assimilated meteorology: Model description and evaluation, J. Geophys. Res., 106, 23073–23095, https://doi.org/10.1029/2001JD000807, 2001 (code is available at http://wiki.seas.harvard.edu/geos-chem, last access: 9 October 2019). a, b
Bousserez, N. and Henze, D. K.: Optimal and scalable methods to approximate the solutions of large-scale Bayesian problems: theory and application to atmospheric inversion and data assimilation, Q. J. Roy. Meteorol. Soc., 144, 365–390, 2018. a
Byrd, R. H., Lu, P., Nocedal, J., and Zhu, C.: A limited memory algorithm for bound constrained optimization, SIAM J. Sci. Comput., 16, 1190–1208, 1995. a
Byrne, B., Jones, D. B. A., Strong, K., Polavarapu, S. M., Harper, A. B., Baker, D. F., and Maksyutov, S.: On what scales can GOSAT flux inversions constrain anomalies in terrestrial ecosystems?, Atmos. Chem. Phys., 19, 13017–13035, https://doi.org/10.5194/acp-19-13017-2019, 2019. a
Byrne, B., Baker, D. F., Basu, S., Bertolacci, M., Bowman, K. W., Carroll, D., Chatterjee, A., Chevallier, F., Ciais, P., Cressie, N., Crisp, D., Crowell, S., Deng, F., Deng, Z., Deutscher, N. M., Dubey, M. K., Feng, S., García, O. E., Griffith, D. W. T., Herkommer, B., Hu, L., Jacobson, A. R., Janardanan, R., Jeong, S., Johnson, M. S., Jones, D. B. A., Kivi, R., Liu, J., Liu, Z., Maksyutov, S., Miller, J. B., Miller, S. M., Morino, I., Notholt, J., Oda, T., O'Dell, C. W., Oh, Y.-S., Ohyama, H., Patra, P. K., Peiro, H., Petri, C., Philip, S., Pollard, D. F., Poulter, B., Remaud, M., Schuh, A., Sha, M. K., Shiomi, K., Strong, K., Sweeney, C., Té, Y., Tian, H., Velazco, V. A., Vrekoussis, M., Warneke, T., Worden, J. R., Wunch, D., Yao, Y., Yun, J., Zammit-Mangion, A., and Zeng, N.: National CO2 budgets (2015–2020) inferred from atmospheric CO2 observations in support of the global stocktake, Earth Syst. Sci. Data, 15, 963–1004, https://doi.org/10.5194/essd-15-963-2023, 2023. a
Casella, G. and Berger, R. L.: Statistical Inference, Thomson Learning Inc, 2 Edn., Duxbury Press, ISBN: 0-534-24312-6, 2002. a, b
Chevallier, F., Breon, F.-M., and Rayner, P. J.: Contribution of the Orbiting Carbon Observatory to the estimation of CO2 sources and sinks: Theoretical study in a variational data assimilation framework, J. Geophys. Res., 112, D09307, https://doi.org/10.1029/2006JD007375, 2007. a, b, c, d, e, f
Chiles, J.-P. and Delfiner, P.: Geostatistics: Modeling Spatial Uncertainty, John Wiley and Sons, John Wiley and Sons, ISBN: 978-0-470-18315-1, 2012. a, b
Clark, D. B., Mercado, L. M., Sitch, S., Jones, C. D., Gedney, N., Best, M. J., Pryor, M., Rooney, G. G., Essery, R. L. H., Blyth, E., Boucher, O., Harding, R. J., Huntingford, C., and Cox, P. M.: The Joint UK Land Environment Simulator (JULES), model description – Part 2: Carbon fluxes and vegetation dynamics, Geosci. Model Dev., 4, 701–722, https://doi.org/10.5194/gmd-4-701-2011, 2011. a
Computational and Information Systems Laboratory: Cheyenne: HPE/SGI ICE XA System (NCAR Community Computing), Boulder, CO, National Center for Atmospheric Research, https://doi.org/10.5065/D6RX99HX, 2022.
Cressie, N.: Statistics for Spatial Data, John Wiley and Sons, Wiley and Sons, ISBN: 978-0471002550, 1993. a
Crowell, S., Baker, D., Schuh, A., Basu, S., Jacobson, A. R., Chevallier, F., Liu, J., Deng, F., Feng, L., McKain, K., Chatterjee, A., Miller, J. B., Stephens, B. B., Eldering, A., Crisp, D., Schimel, D., Nassar, R., O'Dell, C. W., Oda, T., Sweeney, C., Palmer, P. I., and Jones, D. B. A.: The 2015–2016 carbon cycle as seen from OCO-2 and the global in situ network, Atmos. Chem. Phys., 19, 9797–9831, https://doi.org/10.5194/acp-19-9797-2019, 2019. a, b
Deng, F., Jones, D. B. A., Henze, D. K., Bousserez, N., Bowman, K. W., Fisher, J. B., Nassar, R., O'Dell, C., Wunch, D., Wennberg, P. O., Kort, E. A., Wofsy, S. C., Blumenstock, T., Deutscher, N. M., Griffith, D. W. T., Hase, F., Heikkinen, P., Sherlock, V., Strong, K., Sussmann, R., and Warneke, T.: Inferring regional sources and sinks of atmospheric CO2 from GOSAT XCO2 data, Atmos. Chem. Phys., 14, 3703–3727, https://doi.org/10.5194/acp-14-3703-2014, 2014. a, b, c, d
Doucet, A., Godsill, S., and Andrieu, C.: On sequential Monte Carlo sampling methods for Bayesian filtering, Stat. Comput., 10, 197–208, 2000. a
Enting, I., Trudinger, C., and Francey, R.: A synthesis inversion of the concentration and δ13 C of atmospheric CO2, Tellus B, 47, 35–52, 1995. a, b
Flath, H. P., Wilcox, L., Akçelik, V., Hill, J., Waanders, B. V. B., and Ghattas, O.: Fast algorithms for Bayesian uncertainty quantification in large-scale linear inverse problems based on low-rank partial Hessian approximations, SIAM J. Sci. Comput., 33, 407–432, 2011. a, b
Gurney, K. R., Law, R. M., Denning, A. S., Rayner, P. J., Baker, D., Bousquet, P., Bruhwiler, L., Chen, Y.-H., Ciais, P., Fan, S., Fung, I. Y., Gloor, M., Heimann, M., Higuchi, K., John, J., Maki, T., Maksyutov, S., Masarie, K., Peylin, P., Prather, M., Pak, B. C., Randerson, J., Sarmiento, J., Taguchi, S., Takahashi, T., and Yuen, C.: Towards robust regional estimates of CO2 sources and sinks using atmospheric transport models, Nature, 415, 626–630, 2002. a
Halko, N., Martinsson, P., and Tropp, J.: Finding structure with Randomness: Probabilistic algorithms for constructing approximate matrix decompositions, SIAM Rev., 53, 217–288, 2011. a
Harper, A. B., Wiltshire, A. J., Cox, P. M., Friedlingstein, P., Jones, C. D., Mercado, L. M., Sitch, S., Williams, K., and Duran-Rojas, C.: Vegetation distribution and terrestrial carbon cycle in a carbon cycle configuration of JULES4.6 with new plant functional types, Geosci. Model Dev., 11, 2857–2873, https://doi.org/10.5194/gmd-11-2857-2018, 2018. a
Henze, D. K., Hakami, A., and Seinfeld, J. H.: Development of the adjoint of GEOS-Chem, Atmos. Chem. Phys., 7, 2413–2433, https://doi.org/10.5194/acp-7-2413-2007, 2007 (data available at https://wiki.seas.harvard.edu/geos-chem/index.php/Quick_Start_Guide, last access: 9 October 2019). a, b, c, d
Houweling, S., Baker, D., Basu, S., Boesch, H., Butz, A., Chevallier, F., Deng, F., Dlugokencky, E., Feng, L., Ganshin, A., Hasekamp, O., Jones, D., Maksyutov, S., Marshall, J., Oda, T., O’Dell, C. W., Oshchepkov, S., Palmer, P. I., Peylin, P., Poussi, Z., Reum, F., Takagi, H., Yoshida, Y., and Zhuravlev, R.: An intercomparison of inverse models for estimating sources and sinks of CO2 using GOSAT measurements, J. Geophys. Res.-Atmos., 120, 5253–5266, 2015. a
Jet Propulsion Laboratory: CO2 virtual science data environment, California Institute of Technology [data set], https://co2.jpl.nasa.gov/, last access: 12 October 2019. a
Kalmikov, A. G. and Heimbach, P.: A Hessian-based method for uncertainty quantification in global ocean state estimation, SIAM J. Sci. Comput., 36, S267–S295, https://doi.org/10.1137/130925311, 2014. a, b, c
Kalnay, E.: Atmospheric modeling, data assimilation and predictability, Cambridge University Press, ISBN: 9780521796293, 2003. a, b
Lanczos, C.: An iteration method for the solution of the eigenvalue problem of linear differential and integral operators, J. Res. Nat. Bur. Stand., 45, 255–282, 1950. a
Liu, J., Bowman, K., Lee, M., Henze, D. K., Bousserez, N., Brix, H., Collatz, J. G., Menemenlis, D., Ott, L., Pawson, S., Jones, D., and Nassar, R.: Carbon Monitoring system flux estimation and attribution: impact of ACOS-GOSAT X sampling on the inference of terrestrial biospheric sources and sinks, Tellus B, 66, 22486, https://doi.org/10.3402/tellusb.v66.22486, 2016. a, b, c, d, e
Maclean, J. and Vleck, E. S. V.: Particle filters for data assimilation based on reduced-order data models, Q. J. Roy. Meteorol. Soc., 147, 1892–1907, 2021. a
National Institute for Environmental Studies (NIES): GOSAT Data Archive Service, NIES [data set], https://data2.gosat.nies.go.jp, last access: 12 October 2019. a
O'Dell, C. W., Connor, B., Bösch, H., O'Brien, D., Frankenberg, C., Castano, R., Christi, M., Eldering, D., Fisher, B., Gunson, M., McDuffie, J., Miller, C. E., Natraj, V., Oyafuso, F., Polonsky, I., Smyth, M., Taylor, T., Toon, G. C., Wennberg, P. O., and Wunch, D.: The ACOS CO2 retrieval algorithm – Part 1: Description and validation against synthetic observations, Atmos. Meas. Tech., 5, 99–121, https://doi.org/10.5194/amt-5-99-2012, 2012. a, b
Peters, W., Jacobson, A. R., Sweeney, C., Andrews, A. E., Conway, T. J., Masarie, K., Miller, J. B., Bruhwiler, L. M., Pétron, G., Hirsch, A. I., et al.: An atmospheric perspective on North American carbon dioxide exchange: CarbonTracker, P. Natl. Acad. Sci. USA, 104, 18925–18930, 2007 (data available at https://gml.noaa.gov/ccgg/carbontracker/, last access: 9 October 2019). a, b
Petra, N., Martin, J., Stadler, G., and Ghattas, O.: A computational framework for infinite-dimensional Bayesian inverse problems, Part II: stochastic newton MCMC with application to ice sheet flow inverse problems, SIAM J. Sci. Comput., 36, A1525–A1555, 2014. a
Potthast, R., Walter, A., and Rhodin, A.: A Localized Adaptive Particle Filter within an Operational NWP Framework, Mon. Weather Rev., 147, 346–362, 2018. a
Rodgers, C. D.: Inverse Methods for Atmospheric Sounding, World Scientific Publishing, ISBN: 9789810227401, 2000. a, b, c, d, e, f
Vasco, D., Pulliam, R. J., and Johnson, L. R.: Formal inversion of ISC arrival times for mantle P-velocity structure, Geophys. J. Int., 113, 586–606, 1993. a
Wainwright, M. J.: High-Dimensional Statistics, Cambridge University Press, ISBN: 9781108498029, 2019. a
Zammit-Mangion, A., Bertolacci, M., Fisher, J., Stavert, A., Rigby, M., Cao, Y., and Cressie, N.: WOMBAT v1.0: a fully Bayesian global flux-inversion framework, Geosci. Model Dev., 15, 45–73, https://doi.org/10.5194/gmd-15-45-2022, 2022. a
- Abstract
- Introduction
- Monte Carlo method exposition, analysis, and uncertainty quantification
- Numerical examples
- Conclusions
- Appendix A: Supporting algebraic results
- Code availability
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References
- Abstract
- Introduction
- Monte Carlo method exposition, analysis, and uncertainty quantification
- Numerical examples
- Conclusions
- Appendix A: Supporting algebraic results
- Code availability
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Financial support
- Review statement
- References