the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 07 Sep 2021
| 07 Sep 2021
Quantification of uncertainties in the assessment of an atmospheric release source applied to the autumn 2017 106Ru event
Joffrey Dumont Le Brazidec
Marc Bocquet
Olivier Saunier
Yelva Roustan
Using a Bayesian framework in the inverse problem of estimating the source of an atmospheric release of a pollutant has proven fruitful in recent years. Through Markov chain Monte Carlo (MCMC) algorithms, the statistical distribution of the release parameters such as the location, the duration, and the magnitude as well as error covariances can be sampled so as to get a complete characterisation of the source. In this study, several approaches are described and applied to better quantify these distributions, and therefore to get a better representation of the uncertainties. First, we propose a method based on ensemble forecasting: physical parameters of both the meteorological fields and the transport model are perturbed to create an enhanced ensemble. In order to account for physical model errors, the importance of ensemble members are represented by weights and sampled together with the other variables of the source. Second, once the choice of the statistical likelihood is shown to alter the nuclear source assessment, we suggest several suitable distributions for the errors. Finally, we propose two specific designs of the covariance matrix associated with the observation error. These methods are applied to the source term reconstruction of the 106Ru of unknown origin in Europe in autumn 2017. A posteriori distributions meant to identify the origin of the release, to assess the source term, and to quantify the uncertainties associated with the observations and the model, as well as densities of the weights of the perturbed ensemble, are presented.
- Article
(5022 KB) - Full-text XML
- BibTeX
- EndNote





1.1 Bayesian inverse modelling for source assessment
The inverse modelling of a nuclear release source is an issue fraught with uncertainties (Abida and Bocquet, 2009). Variational techniques (Saunier et al., 2013; Bocquet, 2012), which only provide a deterministic and thus unique solution to the problem, miss valuable information such as other potential sources. On the other hand, probabilistic methods develop stochastic solutions able to capture all information from the data. In particular, Bayesian methods have proven to be very efficient in source term estimation (STE) problems. Several techniques such as the iterative variational Bayes method (Tichý et al., 2016) tested using data from the European Tracer Experiment (ETEX), or an adaptive scheme based on importance sampling (Rajaona et al., 2015) and tested on the Fusion Field Trials 2007 experiment, have been developed. Sampling using Markov chain Monte Carlo (MCMC) methods is a very popular technique, since it allows the posterior distribution of the source to be directly assessed. It has been applied by Delle Monache et al. (2008) to estimate the Algeciras incident source location. Keats et al. (2007) sampled the source parameters of a complex urban environment with the help of the Metropolis–Hastings algorithm. The emissions of xenon-133 from the Chalk River Laboratories medical isotope production facility were reconstructed with their location by Yee et al. (2014). Various Bayesian methods including MCMC techniques are used by Liu et al. (2017) to assess the source term of the Chernobyl and Fukushima Daiichi accidents and their associated uncertainties.
1.2 Ensemble methods
A major source of uncertainties in the inverse modelling for source term estimation of nuclear accidents originates from the meteorological fields and the transport models (Sato et al., 2018) which are used to simulate the plume of the emission. Weather forecast uncertainties arise from errors in the initial conditions and approximations in the construction of the numerical model. They can be evaluated through the use of an ensemble forecast (Leith, 1974). Several realisations of the same forecast are considered, where for each realisation, the initial condition and the numerical model are perturbed. These forecasts can then be combined to generate a single forecast. More specifically, ensemble members can be linearly combined, where each member of the ensemble is given a weight. In a deterministic approach, weights can be computed using assorted methods such as machine learning (Mallet et al., 2009) or least squares algorithms (Mallet and Sportisse, 2006). For weather forecasting, these weights can depend on past observations or analyses (Mallet, 2010). As developed later in this paper in Sect. 2.3, the study of the weights provides access to the uncertainty in meteorological models. The uncertainty due to the transport model can also be studied through ensemble methods such as that of Delle Monache and Stull (2003), who use a mixture of diverse air quality models. We propose in this paper a new technique to estimate the weights associated with ensemble members.
1.3 Probabilistic description of the problem
We wish to parametrise the distribution of the variable vector x describing the source of a release. In the case of a point-wise source of unknown location, the most important variables describing the source are the coordinates longitude–latitude (x1,x2), the vector ln q (where each component corresponds to the logarithm of the release q on a given time interval, e.g. an hour or a day), and the covariance matrix R containing the model–measurement error variances defined below. The posterior probability distribution is written with the help of Bayes' theorem as
with y the observation vector, usually a set of air concentration measurements, and x the source variable vector. The first term p(y|x) of Eq. (1) corresponds to the likelihood distribution quantifying the fit of a statistical model (here the characterisation of the source x) with the data (the observation vector y). The second term, the prior p(x), describes the probability distribution of prior knowledge on the source vector before considering data. Once the posterior probability distribution is known up to a normalisation constant, several sampling techniques can be applied to it (Liu et al., 2017).
The shape of the posterior distribution strongly depends on the uncertainties related to the data and the modelling choices, which include the meteorological data and transport models definitions as well as the likelihood definition. The objective of this study is to investigate the various sources of uncertainties compounding the problem of source reconstruction, and to propose solutions to better evaluate them, i.e. to increase our confidence in the reconstructed posterior distribution. The quantification of the uncertainties largely depends on the definition of the likelihood and its components (for example, a corresponding covariance matrix). The choice of the likelihood is the concern of Sect. 2.1. As mentioned above, the likelihood term quantifies the fitness between the measurements y and a given transformation of the source x. To make these two quantities comparable, a set of modelled concentrations corresponding to the observations are computed. These concentrations, also called predictions, are the results of a simulation of the dispersion of the source x and depend on the parametrisation of the transport model and on the meteorological fields.
In this paper and in the case of a source of unknown location, the predictions are written as where H is the observation operator, the matrix representing the resolvent of the atmospheric transport model, and its definition for a source of coordinates x1,x2. Therefore, the observation operator does vary linearly with q. However, H is not linear in the coordinates. When the coordinates are unknown, they may be investigated in a continuous space. The computation of a matrix for a specific couple of coordinates being expensive, a set of observation operators linked to specific locations is computed on a regular mesh G prior to the Bayesian sampling presented in Sect. 3.2.3. The observation operators are therefore interpolated from the set of observation operators pre-computed on G.
Equation (1) can be expanded as
where uncertainties are embodied in
-
the observations y;
-
the physical models: the meteorological fields m and the dispersion H;
-
the likelihood definition: its choice and the design of its associated error covariance matrix R;
-
the representation error: the release rates q as a discrete vector (while the release is a continuous phenomenon), the observation operator as an interpolation, and the observations for which the corresponding predictions are calculated in a mesh containing them;
-
the choice of the priors.
In this paper, we focus on the uncertainties emanating from the physical models and the definition of the likelihood.
1.4 Objectives of this study
This study is a continuation from a previous study from the authors (Dumont Le Brazidec et al., 2020). It aims to explore the various sources of uncertainty which are compounding the inverse problem and propose solutions to better evaluate them: three key issues are investigated. First, in Sect. 2.1, we investigate the design of the likelihood distribution, which is a key ingredient in the definition of the posterior distribution. Second, we propose two new designs of the likelihood covariance matrix to better evaluate errors in Sect. 2.2. Finally, in Sect. 2.3, we describe an ensemble-based method for taking into account the uncertainties related to the meteorological fields and atmospheric transport model: H is built as a weighted sum of observation operators created out of diverse physical parameters.
Subsequently, these three sources of uncertainty are explored in an application of source term estimation of the 106Ru release in September 2017. First, a description of the context, the observation dataset, and the release event are provided in Sect. 3.1. Then the parametrisation of the physical model is presented in Sect. 3.2.1. Finally, the results of the successive applications of the assorted methods described in Sect. 2, combined or not, are presented in Sect. 3.3. A summary of the various configurations of each application is proposed in Sect. 3.3.1. Conclusions on the contribution of each method are finally proposed.
2.1 Choice of the likelihood
In the field of source assessment, and more precisely radioactive material source assessment, the likelihoods are often defined as Gaussian (Yee, 2008; Winiarek et al., 2012; Saunier et al., 2013; Bardsley et al., 2014; Yee et al., 2014; Winiarek et al., 2014; Rajaona et al., 2015; Tichý et al., 2016), or adapted from a Gaussian to consider non-detections and false alarms (De Meutter and Hoffman, 2020), or more recently log-normal (Delle Monache et al., 2008; Liu et al., 2017; Saunier et al., 2019; Dumont Le Brazidec et al., 2020) or akin to a log-normal (Senocak et al., 2008). The multivariate Gaussian probability density function (pdf) of y, of mean Hx and covariance matrix R, is written as
In this section, we assume that the covariance matrix R is equal to rI, where r is a positive coefficient. The cost function, i.e. the negative of the log-likelihood, of the Gaussian probability density function (pdf) is written (up to a normalisation constant) as
with Nobs the number of observations. The cost function is a matter of judgement; it measures how detrimental a difference between an observation and a prediction is. When the observations and the predictions are equal, the cost corresponding to the likelihood should be zero and it should increase when the difference between the observation and the prediction values grows.
With the assumption R=rI, choosing a Gaussian likelihood penalises the largest errors to an extent that smaller errors are negligible: the Gaussian cost function value of an observation–prediction couple () is a hundred of times greater than of (). In other words, with a Gaussian likelihood and the assumption R=rI, inverse modelling is dominated by the most significant measurements in real-case studies.
The whole set of measurements should provide information: if the inversion is dominated by the few measurements with the largest errors (which may possibly be outliers), valuable information provided by the other measurements may be missed. More generally, the following inventory lists the criteria that a good likelihood choice under the assumption R=rI (or any important simplification of R) for nuclear source assessment should fulfil:
-
positive domain of definition: should be defined for values on the semi-infinite interval since the observations and predictions are all positive by nature;
-
symmetry between the prediction vector and the observation vector, i.e. . The couple should have the same penalty as ;
-
close to proportionality: the ratio of the cost function value of a couple with a couple should be close to 1 as a general rule. This criterion is a simplification since the distribution of errors might be more complex than simply multiplicative;
-
existence of a covariance matrix, and of a term able to play the role of the modelled predictions. Indeed, the likelihood measures the difference between the observations and the predictions, which should therefore appear as a parameter of the distribution. Distributions with a location parameter comply with this requirement.
In particular, three distributions were found to satisfy these diverse criteria: the log-normal distribution already used in several studies, the log-Laplace and the log-Cauchy distributions, which have for cost functions (up to a normalisation constant) (Satchell and Knight, 2000; McDonald, 2008).
where yt is a positive threshold vector to ensure that the logarithm function is defined for zero observations or predictions. The l2 and l1 norms are defined as and with R diagonal, respectively. These three distributions are subsumed by the generalised beta prime (or GB2) (Satchell and Knight, 2000; McDonald, 2008) and share a common point; all three are shaped around the subtraction of the logarithm of the observation by the logarithm of the prediction. Due to the logarithmic property , several criteria previously defined are met. First, the cost is a function of the ratio of the observation to the prediction. Second, these functions are defined with a location parameter which plays the role of the modelled prediction ln ((Hx)i+yt). And finally, with the help of a square or an absolute value, a symmetry between the observation and the prediction is guaranteed. Each of these choices requires a threshold (and even two for the log-Cauchy case, discussed at the end of this section) whose value significantly impacts the results. The log-normal and log-Cauchy distributions are compared for Bayesian source estimation by Wang et al. (2017).
Their difference lies in the treatment of the relative quantity . With the l2 norm, the log-normal drives most of the penalty on the large (relative) differences and removes almost all penalty from the small differences. With the l1 norm, the log-Laplace curve of the relative quantity is flatter in comparison. This translates in the fact that the inverse modelling will not be sensitive to one couple in particular, even if for this couple the difference between the observation and the prediction is large. The motive therefore for using log-Laplace is to avoid having outliers driving the entire sampling, i.e. driving the entire search of the source. The log-Cauchy distribution is the one with the most interesting behaviour and mixes log-normal and log-Laplace natures. The logarithm mitigates the penalty of large differences but also removes any penalty from the small differences. The rationale of using the log-Cauchy distribution is consequently to avoid outliers, but at the same time to avoid taking into account negligible differences.
For all choices, the value of yt is crucial to evaluate the penalty on a couple involving a zero observation or prediction. In other words, it calculates how the cost of a zero observation and a non-zero prediction (or the contrary) should compare to a positive couple. We consider that the penalty on a couple should be a large multiple of the penalty on . As a consequence, it can be deduced that a “good” threshold for the log-normal distribution in a case involving important quantities released should lie between 0.5 and 3 mBq m−3. Using the same principle, acceptable thresholds for the log-Laplace or the log-Cauchy distributions range between 0.1 and 0.5 mBq m−3.
We should also consider that the log-Cauchy distribution needs a second threshold jt to be properly defined. Indeed, if for a couple both observation yi and prediction (Hx)i are equal (usually both equal to zero), then r will naturally tend towards 0 so that 𝒥log-Cauchy tends to −∞ as can be seen in Eq. (6) with jt equal to zero. To prevent that, we can define jt=0.1 mBq m−3 and
with cref=1 mBq m−3.
As will be shown later, the choice of the likelihood has in practice a significant impact on the shape of the posterior distribution. Hence, to better describe the uncertainties of the problem, the approach proposed here is to combine and compare the distributions obtained with these three likelihoods.
2.2 Modelling of the errors
The likelihood definition, and therefore the posterior distribution shape, is also greatly impacted by the modelling choice of the error covariance matrix R. The matrix is of size Nobs×Nobs. In real nuclear case studies, the number of observations can be important, whereas Bayesian sampling methods can usually estimate efficiently only a limited number of variables. To limit the number of variables, most of the literature (Chow et al., 2008; Delle Monache et al., 2008; Winiarek et al., 2012; Saunier et al., 2013; Rajaona et al., 2015; Tichý et al., 2016; Liu et al., 2017) describes the error covariance matrix as a diagonal matrix with a unique and common diagonal coefficient. This variance accounts for the observation (built-in sensor noise and bias), models (uncertainty of the meteorological fields and transport model), and representation error between an observation and a modelled prediction (e.g. Rajaona et al., 2015). Saunier et al. (2019) analyse the impact of such a choice on the same case study as this paper. Indeed, the error is a function of time and space and is obviously not common for every observation–prediction couple.
This critical reduction can lead to paradoxes. With R=rI, the variance r captures an average of the observation–prediction couples error variances. As seen in Appendix A, some observations can tamper the set of measurements and artificially reduce the value of r, which prevents the densities of the variables being well spread. Specifically, let us consider the non-discriminant observations. These are observations for which, for any probable source x, the observation is almost equal to the prediction. In other words, a non-discriminant observation is an observation which never contributes to discriminating any probable source from another. It is an observation for which, if R was modelled as a diagonal matrix with Nobs independent terms, the variance ri corresponding to this observation would be very small or zero. If we model R as rI, then r, capturing an average of the Nobs variances ri, decreases artificially. To deal with the existence of these observations, we propose to use two variances r1 and rnd. The discriminant observations will be associated with the variance r1 while the non-discriminant observations will be associated with the variance rnd during the sampling process. Necessarily then, rnd tends to a very small value.
In the following, we refer to this algorithm as the observation-sorting algorithm. A justification of the use of this clustering using the Akaike information criterion (AIC) is proposed in Appendix B.
We now propose a second approach to improve the design of the covariance matrix R and the estimation of the uncertainties. We propose to cluster observations according to their spatial position in k groups, where observations of the same cluster are assigned the same observation error variance. This proposal is based on the fact that the modelling part of the observation error is a spatially dependent function. With this clustering, we have the source variables of interest, and R as a diagonal matrix where the ith diagonal coefficient is assigned a rj with according to the cluster to which the observation yi belongs.
Using both methods, the set of variable x to retrieve becomes .
2.3 Modelling of the meteorology and transport
As explained in Sect. 1.3, the linear observation operator H is computed with an atmospheric transport model, which takes meteorological fields as inputs. More precisely, the Eulerian ldX model, a part of IRSN's C3X operational platform (Tombette et al., 2014), validated on the Algeciras incident and the ETEX campaign, as well as on the Chernobyl accident (Quélo et al., 2007) and the Fukushima accident (Saunier et al., 2013), is the transport model used to simulate the dispersion of the plume, and therefore to build the observation operators. To improve the accuracy of the predictions, and therefore reduce the uncertainties, several observation operators computed with various physical parameters configuring the transport model and meteorological fields can be linearly combined. This combination then produces a single prediction forecast, hopefully more skilful than any individual prediction forecast.
First, ensemble weather forecasts can be used to represent variability in the meteorological fields. The members of the ensemble are based on a set of Nm models, where each model can have its own physical formulation. Second, considering a meteorology with little rainfall, three parameters of the transport model in particular can have an important impact on the dispersion of a particle (Girard et al., 2014) and are subject to significant uncertainties: the dry deposition, the height of the release, and the value of the vertical turbulent diffusion coefficient (Kz).
Therefore, to create an ensemble of observation operators with both uncertainty in the meteorological fields and in the transport parametrisation, a collection of observation operators can be computed out of four parameters. More specifically, each Hi with is the output of a transport model parametrised by
-
choosing a member from an ensemble of meteorological fields and hence a discrete value in [1,Nm];
-
a constant deposition velocity in ;
-
a distribution of the height of the release between two layers defined between 0 and 40 m, and between 40 and 120 m, the space being discretised vertically in layers of various heights as described in Table 1;
-
a multiplicative constant on the Kz values chosen in [0.333,3],
where each parameter range has been set up based on the work of Girard et al. (2014), and deposition and Kz processes are described in Table 1. The ensemble of observation operators is therefore computed from a collection of parameters. This collection is obtained from sampling the values of the parameters inside the intervals.
Once the set of operators has been built, the idea is to combine them linearly to get a more accurate forecast. A weight wi can be associated with each observation operator of the ensemble:
which results in combining linearly the predictions of each member of the ensemble. Each weight wi is a positive variable to be retrieved. The weights can be included in the set of variables sampled by the MCMC algorithm. They are dependent on each other through the necessary condition so this means Ne−1 weight variables will be added to .
Several methods are used in Sect. 3.3.4 to explore reliability, accuracy (level of agreement between forecasts and observations), skill, discrimination (different observed outcomes can be discriminated by the forecasts), resolution (observed outcomes change as the forecast changes), and sharpness (tendency to forecast extreme values) of probabilistic forecasts (Delle Monache et al., 2006). Rank histograms are used to evaluate the spread of an ensemble. Reliability diagrams (graphs of the observed frequency of an event plotted against the forecast probability of an event) and ROC curves (which plot the false positive rate against the true positive rate using several probability thresholds) are used to measure the ability of the ensemble to discriminate (Anderson, 1996).
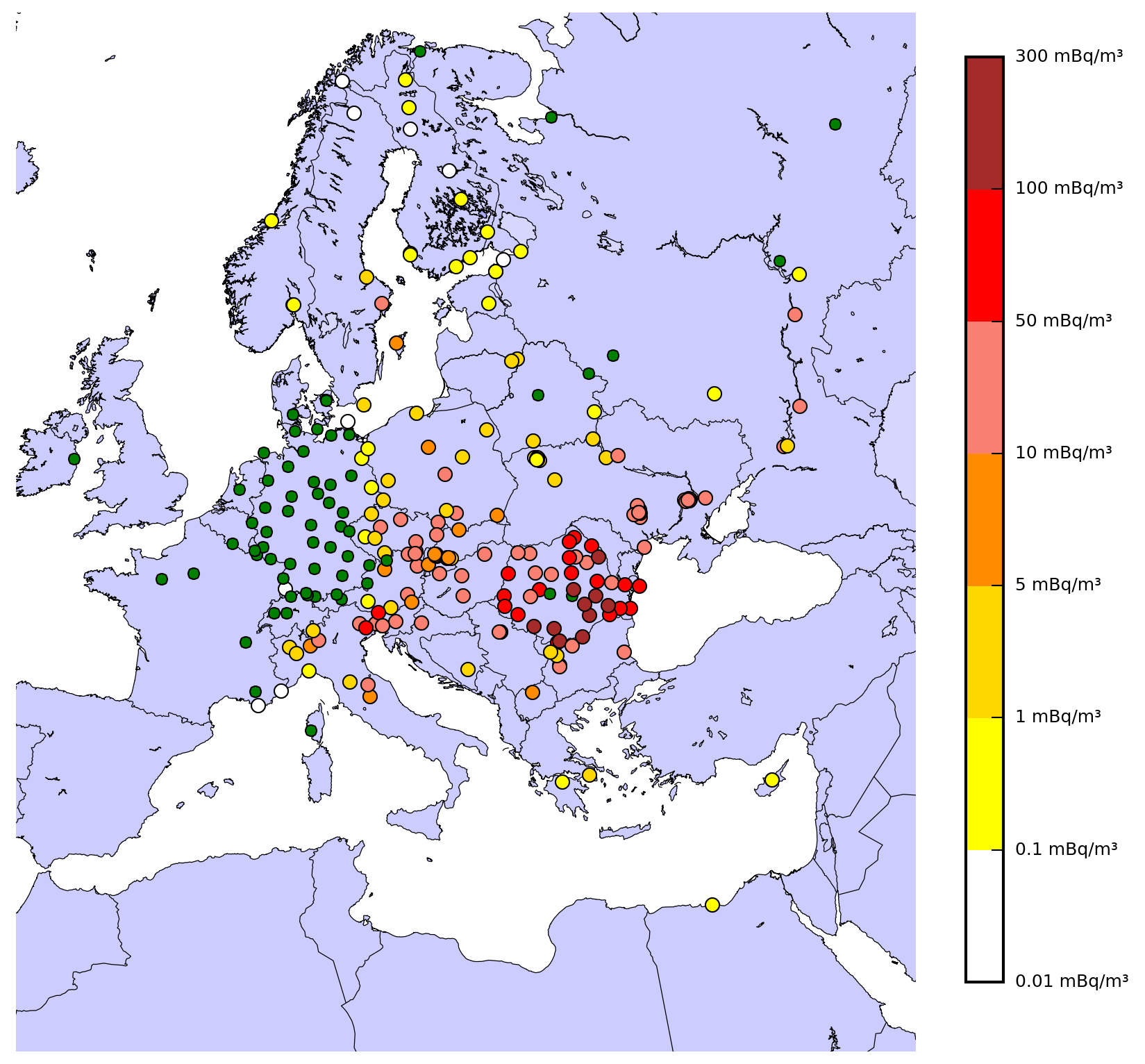
Figure 1Maximum air concentrations of 106Ru observed over Europe in mBq m−3. Green points measured concentrations below the detection limit.
Table 1Main configuration features of the ldX dispersion simulations for the 106Ru detection event, with the deterministic observation operator or the ensemble of observation operators. The nested domain is the domain where the origin of the release is assumed a priori.
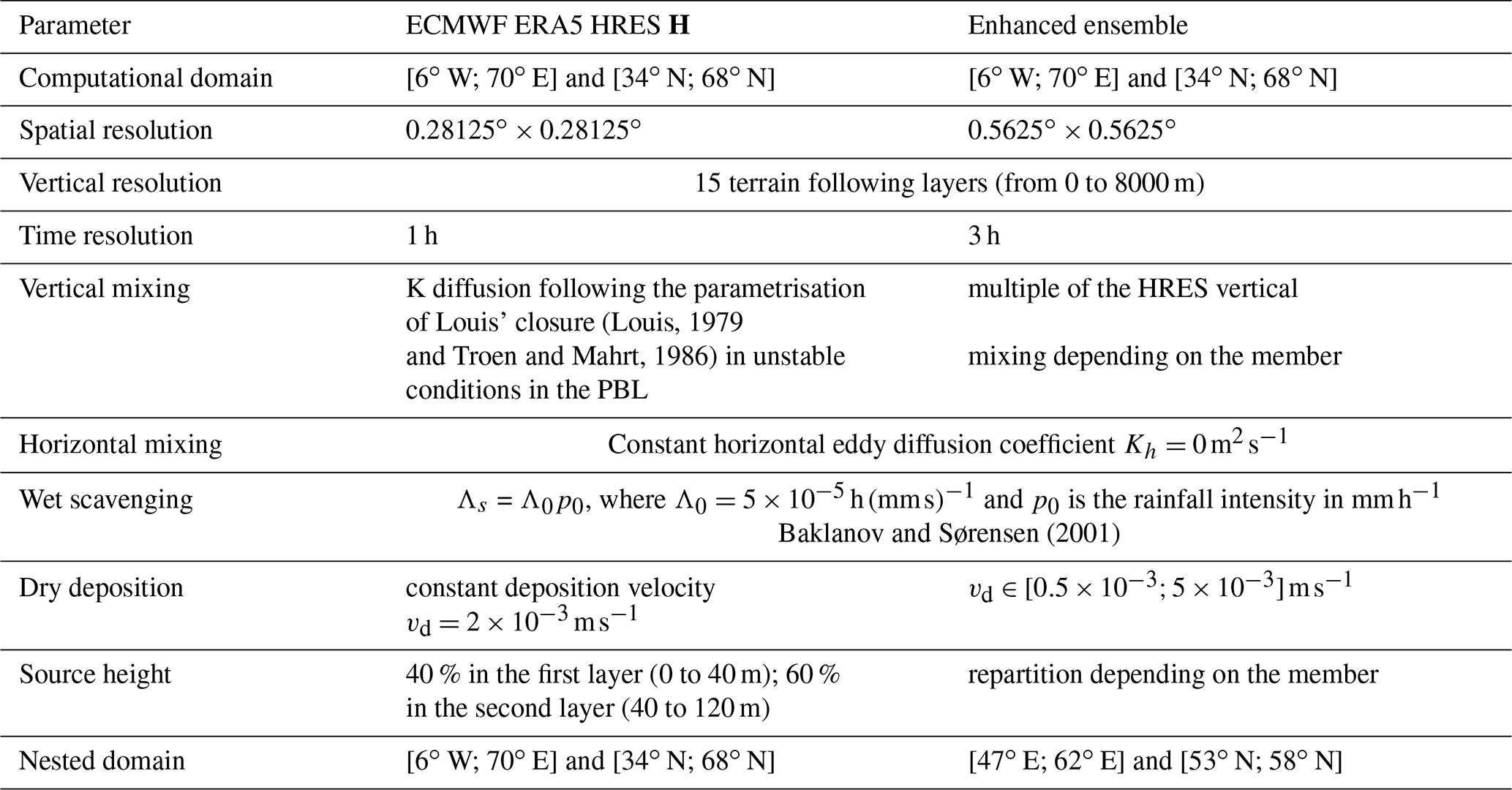
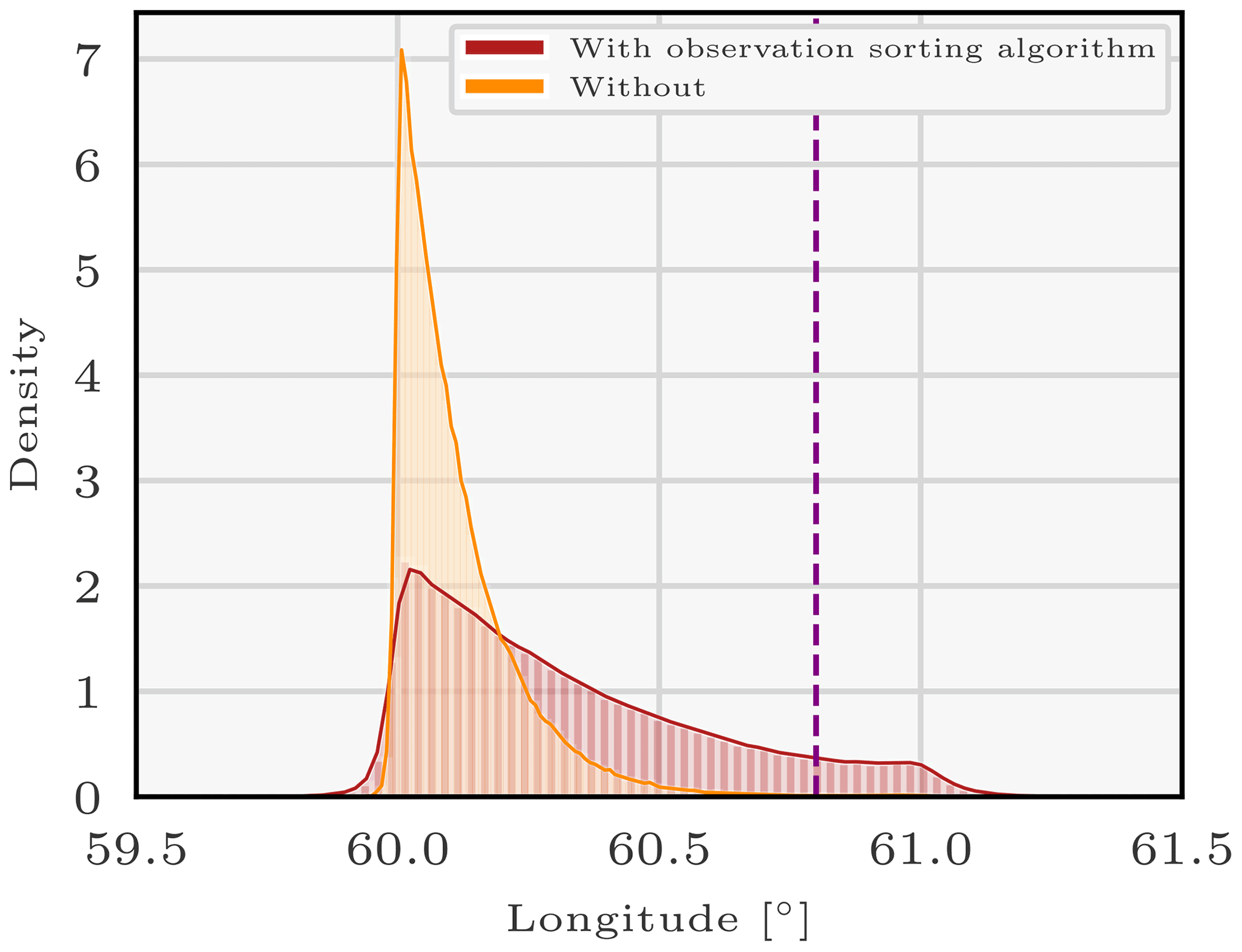
Figure 2Density of the longitude for a log-Laplace likelihood with threshold 0.1 mBq m−3 of the 106Ru source sampled with the 30 first members of the enhanced ensemble of observation operators using the parallel tempering method with or without the help of the observation-sorting algorithm. The purple vertical bar represents the longitude of the Mayak nuclear complex.
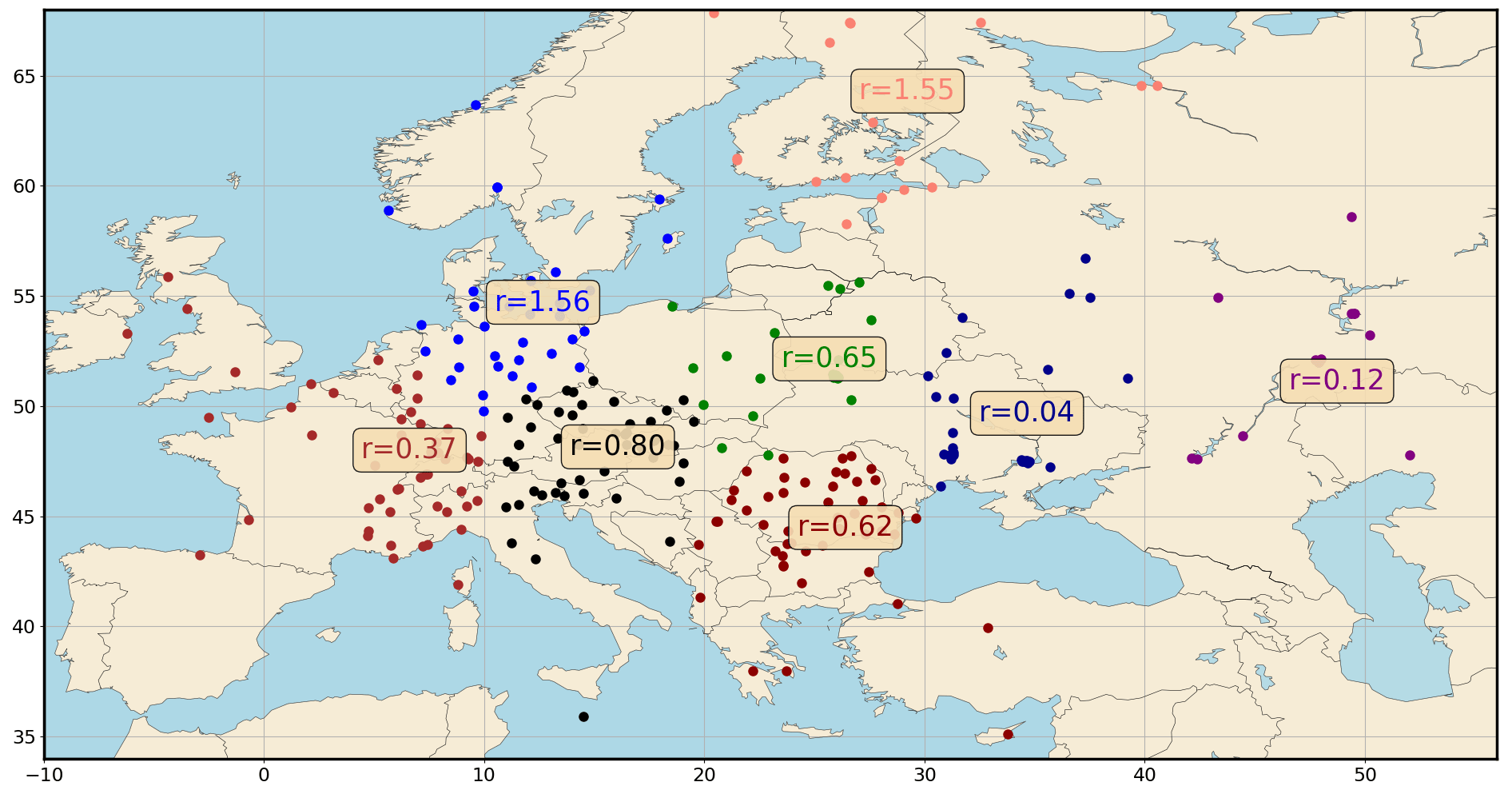
Figure 3106Ru observations spatially clustered with a k means algorithm (k=9). The means of the corresponding nine variance distributions have been computed using a parallel tempering algorithm for a log-normal distribution with a threshold equal to 0.5 mBq m−3. The observation-sorting algorithm is applied and “eliminates” the low-uncertainty observations.
3.1 Context
In this section, the methods are applied to the detection event of 106Ru in Europe in autumn 2017. We first provide a brief context for the event and a review of earlier studies and describe the observation dataset and the model.
Small quantities of 106Ru were measured by several European monitoring networks between the end of September and the beginning of October 2017. Inquiries to locate the source, the origin of the 106Ru being unknown, have been carried out, based on the radionuclide measurements. Correlation methods are used by Kovalets et al. (2020) to retrieve the location of the source. Saunier et al. (2019) apply deterministic inverse modelling methods to reconstruct the most probable source and release: southern Ural is identified as the most likely geographical location, and the total release in the atmosphere is estimated to be 250 TBq. The location, release, and errors are also investigated by Dumont Le Brazidec et al. (2020), Tichý et al. (2021), and Western et al. (2020) using Bayesian methods. De Meutter et al. (2021) propose a methodology to retrieve the model error in the 106Ru case.
The concentration measurements used in this study are available in Masson et al. (2019). The dataset has more than 1000 observations of 106Ru with detection levels from a few µBq m−3 to more than 170 mBq m−3 in Romania. It is described in Fig. 1.
3.2 Modelling
3.2.1 Physical parametrisation
All simulations, described in Sect. 3.3, are driven using the ECMWF (European Centre for Medium-Range Weather Forecasts) ERA5 meteorological fields (Hersbach et al., 2020). A single observation operator H is built with the high-resolution forecast (HRES) reanalysis, in order to study the relevance of the methods presented in Sects. 2.1 and 2.2. An enhanced ensemble of 50 observation operators is built following the methodology of Sect. 2.3, where the ensemble of meteorological fields is the ERA5 EDA (Ensemble Data Assimilation) of 10 members. As explained in Sect. 2.3, each observation operator of this enhanced ensemble is the output of the transport model based on a random member of the ERA5 EDA and a random physical parametrisation. Table 1 refers to the parameters of the ldX dispersion simulations. The choice of parameters is based on the analysis carried out by Saunier et al. (2019) and Dumont Le Brazidec et al. (2020). As seen in Sect. 2.3 and Table 1, the vertical mixing of each member of the enhanced ensemble is a random multiple (between and 3) of the corresponding ECMWF EDA member vertical mixing. Furthermore, the constant dry deposition velocity and the distribution of the height of the release between the two first vertical layers of each member is unique and specific to this member. On most measurement stations, there was no rain event on the passage of the plume except for Scandinavia and Bulgaria. This suggests that wet deposition has a weak influence on the simulations, compared to the other processes.
Simulations are performed forward in time from 22 September 2017 at 00:00 UTC to 13 October 2017, which corresponds to the time of the last observation with resolutions defined in the Table 1. The HRES domain grid G of computation of the operators H corresponds to the nested domain of Table 1 and has been chosen based on previous works from the authors (Saunier et al., 2019; Dumont Le Brazidec et al., 2020). The enhanced ensemble domain grid where origin of the release is considered is of smaller extent due to computation power limitations and focuses on the most probable geographical domains of origin of the release, inferred from the HRES results presented in Sect. 3.3.3. The chosen mesh spatial resolution of G is 0.5∘ for the simulations with the ECMWF ERA5 HRES observation operator and 1∘ with the enhanced ensemble of observation operators. The logarithm of the release q is defined as a vector of size Nimp=9 daily release rates from 22 to 30 September, as explained in Dumont Le Brazidec et al. (2020). Therefore, ldX is run for each grid point of G and for each day between 22 and 30 September to build the observation operators.
3.2.2 Choice of the priors
In a Bayesian framework, the prior knowledge on the control variables for the 106Ru source must be described. Following Dumont Le Brazidec et al. (2020), and because no prior information is available, longitude, latitude, observation error variance, and member weights prior probabilities are assumed to be uniform. Lower and upper bounds of the uniform distribution on the coordinates are defined by the nested domain of Table 1. The lower bound of the observation error variance is 0 and the upper bound is chosen as a very high and unrealistic value. Lower and upper bounds of members' weight probabilities are 0 and 1. The independent priors of the release rates are chosen as log-gamma distributions to prevent the values of the release increasing unrealistically: the scale term is chosen as e30 and the shape parameter as 0 (Dumont Le Brazidec et al., 2020).
3.2.3 Parallel tempering algorithm
We rely on Markov chain Monte Carlo (MCMC) algorithms to sample from the target p(x|y). MCMC methods are asymptotically exact sampling methods not reliant on closed-form solutions. They are based on the use of Markov chains having as invariant distribution the posterior distribution of interest. A Markov chain is a stochastic model that describes a sequence of possible events that can converge to a distribution. Thus, after a sufficient time, the Markov chain samples values of this distribution. The convergence of a popular MCMC algorithm such as the Metropolis–Hastings (MH) algorithm can be hampered by the encounter of local minima and be delayed (Dumont Le Brazidec et al., 2020). To overcome this issue, the parallel tempering algorithm (Swendsen and Wang, 1986) is employed. Also called Metropolis-coupled Markov chain Monte Carlo (MCMCMC) or temperature swapping (Earl and Deem, 2005; Baragatti, 2011; Atchadé et al., 2011), it consists of combining several MCMC algorithms (such as MH) at different temperatures, where a temperature is a constant flattening out the posterior distribution. Chains with a flat target distribution avoids being trapped in local minima and provide probable source variable vectors to the “real” chain with no temperature. Details of the implementation applied to our problem can be found in Dumont Le Brazidec et al. (2020).
3.2.4 Parameters of the MCMC algorithm
The transition probabilities used for the random walk of the Markov chains are defined independently for each variable and based on the folded-normal distribution as described by Dumont Le Brazidec et al. (2020). The transition probability of the meteorological member weights is also defined as a folded-normal distribution. Weights are at first updated independently from each other, and then each proposal is updated by the sum of the weights, i.e.
where ℱ𝒩 is the folded-normal distribution, with σw the prior standard deviation of the weights and the value of the weight of the member k before the walk.
The variances of the transition probabilities are chosen based on experimentations and are set to be , σln q=0.03, σr=0.01, and σw=0.0005. All variables are always initialised randomly. Locations of the transition probabilities are the values of the variables at the current step. When the algorithm to discriminate observations presented in Sect. 2.2 is used, we consider that a prediction and an observation can be considered as equal if their difference is less than ϵd=0.1 mBq m−3, which is inferred from receptor detection limits described in Dumont Le Brazidec et al. (2020). Ten chains at temperatures ti=ci with c=1.5 are used in the parallel tempering algorithm.
3.3 Application of the methods
3.3.1 Overview
To see the impacts of the techniques proposed in Sect. 2 (i.e. using diverse likelihoods, new designs of the error covariance matrix, and an ensemble-based method), the pdfs of the variables describing the 106Ru source are sampled from various configurations:
-
Sect. 3.3.2 is an application of the observation-sorting algorithm presented in Sect. 2.2. It provides a comparison between the longitude pdf reconstructed with or without the observation-sorting algorithm to estimate its efficiency.
-
Sect. 3.3.3 is an application of the use of different likelihood functions and strategies to spatially cluster observations in diverse groups. It presents results obtained using the HRES meteorology to analyse the impact of using several likelihood distributions. The observation-sorting algorithm is applied and two cases are explored: no spatial clustering of the observations, , and spatial clustering of the observations with the corresponding modelling of the error covariance matrix R as described in the end of Sect. 2.2: where we use k=9.
-
Sect. 3.3.4 is an application of the use of the ensemble-of-observation-operator strategy presented in Sect. 2.3. The enhanced ensemble with uncertainty on the dispersion parameters based on the ERA5 EDA of 10 members is analysed in Sect. 3.3.4. Afterwards, pdfs of the source variables x are sampled using the enhanced ensemble: . Results are reconstructed with the help of the observation-sorting algorithm and diverse likelihoods.
Note that, when the observation-sorting algorithm is used, in all cases, approximately half of the observations are sorted as non-discriminant.
3.3.2 Study of the interest of the observation-sorting algorithm
We present here an experiment supporting the observation-sorting method. A reconstruction of the source variables is proposed using the enhanced ensemble of observation operators, only on the first 30 members for the sake of computation time. The enhanced ensemble is studied later in Sect. 3.3.4. A log-Laplace likelihood with a threshold equal to 0.1 mBq m−3 is used in two cases: with or without applying the observation-sorting algorithm. The source variable vector is therefore (with observation-sorting algorithm) or (without).
Figure 2 represents the longitude variable pdf of the sources' variable vectors. The red histogram, which represents the longitude pdf in the case where the observation-sorting algorithm is applied, is far more spread out than the case without. It indeed ranges from 60 to 61.2∘ while the orange longitude density (without applying the observation-sorting algorithm) ranges from 60 to 60.6; i.e. the pdf extent with sorting is the double of the spread without.
The mean of the observation error variance r samples in the case without the observation-sorting algorithm is 0.399. In the case with the observation-sorting algorithm, the discriminant observation error variance r1 is equal to 0.63 and the non-discriminant observation error variance rnd tends to a very low value. We denote xwith as the set of sources sampled (and therefore considered as probable) when using the observation-sorting algorithm and xwithout as the set of sources sampled without. For example, a source x in xwith is of longitude x1 in [60,61.2]. By definition of the log-Laplace pdf in Eq. (5), the fact that rnd tends to a very low value confirms that non-discriminant observations are observations which are not able to discriminate between any of the sources in xwith.
What happens when the observation-sorting algorithm is not used (orange histogram), i.e. with the basic design R=rI, is that the observation error variance r is common for all observations. The resulting r=0.399 is therefore a compromise between r1=0.63 and rnd∼0, the variances sampled with the sorting algorithm. In other words, the uncertainty of the discriminant observations is reduced compared to the uncertainty found when applying the sorting algorithm. That is, the confidence in the discriminant observations is artificially high. This is why the extent of the resulting posterior pdfs is reduced compared to the case with the observation-sorting algorithm. More precisely, the probability of the most probable sources (here longitudes between 60 and 60.6) is increased and the probability of the least probable sources is decreased (longitudes between 60.6 and 61.2).
The observation-sorting algorithm is a clustering algorithm that avoids this compromise. Observations always equal to their predictions (i.e. associated with very small observation error variance, or with very high confidence for all probable sources) – the non discriminant observations – are assigned a specific observation error variable. In this way, the uncertainty variance associated with the other observations is far more appropriate. This clustering is totally valid as explained in Appendix B.
Finally, note that sampling the longitude posterior distribution using yd the set of discriminant observations instead of y yields a pdf very similar to the red density in Fig. 2. In other words, considering observations which cannot discriminate between a source of longitude 60 and a source of longitude 60.8 actually decreases the probability of the source of longitude 60.8, which is not justifiable. The significant difference between the two pdfs makes the application of the algorithm necessary.
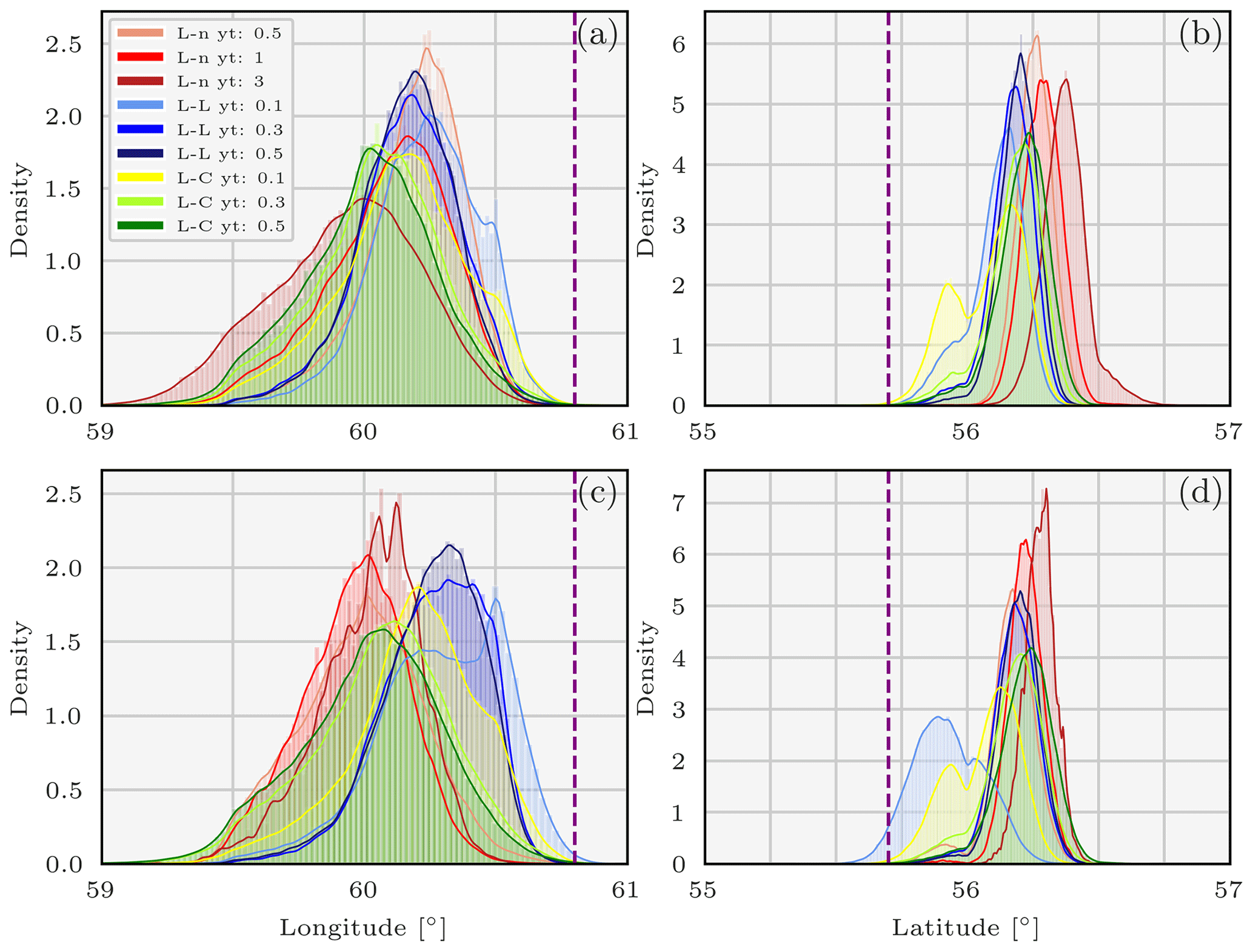
Figure 4Pdfs of the coordinates describing the 106Ru source sampled using the parallel tempering method and the observation-sorting algorithm and for various likelihoods in two scenarios: longitude without (a) and with observation spatial clustering in nine clusters (c) and latitude without (b) and with (d). L-L means log-Laplace, L-n means log-normal, L-C means log-Cauchy, and yt is the likelihood threshold. The purple vertical bars represent the coordinates of the Mayak nuclear complex.
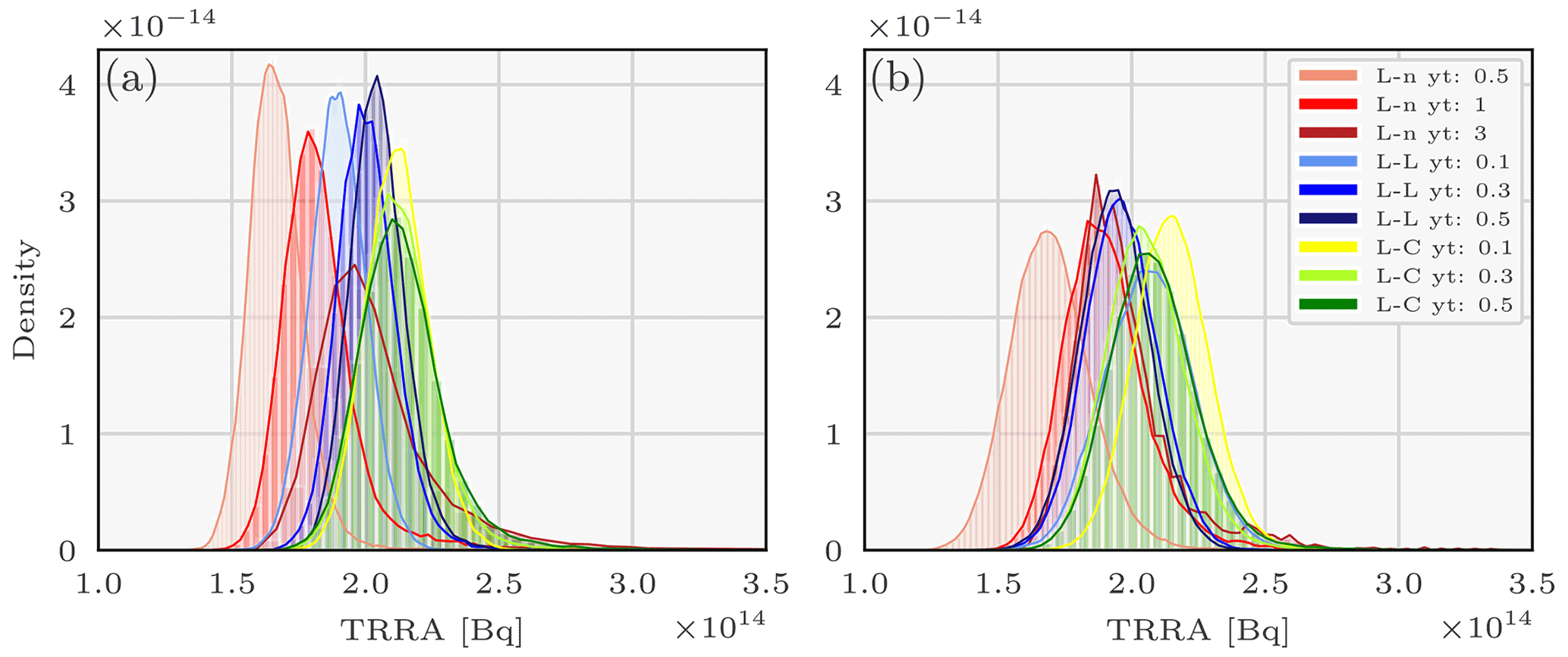
Figure 5Pdfs of the total retrieved released activity (TRRA) describing the 106Ru source sampled using the parallel tempering method and the observation-sorting algorithm and for various likelihoods in two scenarios: without (a) and with observation spatial clustering in nine clusters (b). L-L means log-Laplace, L-n means log-normal, L-C means log-Cauchy, and yt is the likelihood threshold.
3.3.3 Sampling with the HRES data, several likelihoods, the observation-sorting algorithm, and with or without observation spatial clusters
In this section, we study two cases. First, we assess the impact of the choice of the likelihood on the reconstruction of the control variable pdfs (), and second, we investigate how assigning diverse error variance terms to the observations according to a spatial clustering can affect the results (). In this second case, clusters are computed with a k mean algorithm for k=9. Observation clusters are presented in the map below. As can be seen in Fig. 3, the nine variances sampled are diverse. We do not provide explanations of the values of these variances given that the observation-sorting algorithm is used and “eliminates” observations with low uncertainties. Therefore, the variances are only representative of observations with high uncertainties in their subset. However, the figure shows that the variances are very different: the use of a single parameter to represent them all is an important simplification. We now present the reconstruction of the pdfs in the two scenarios.
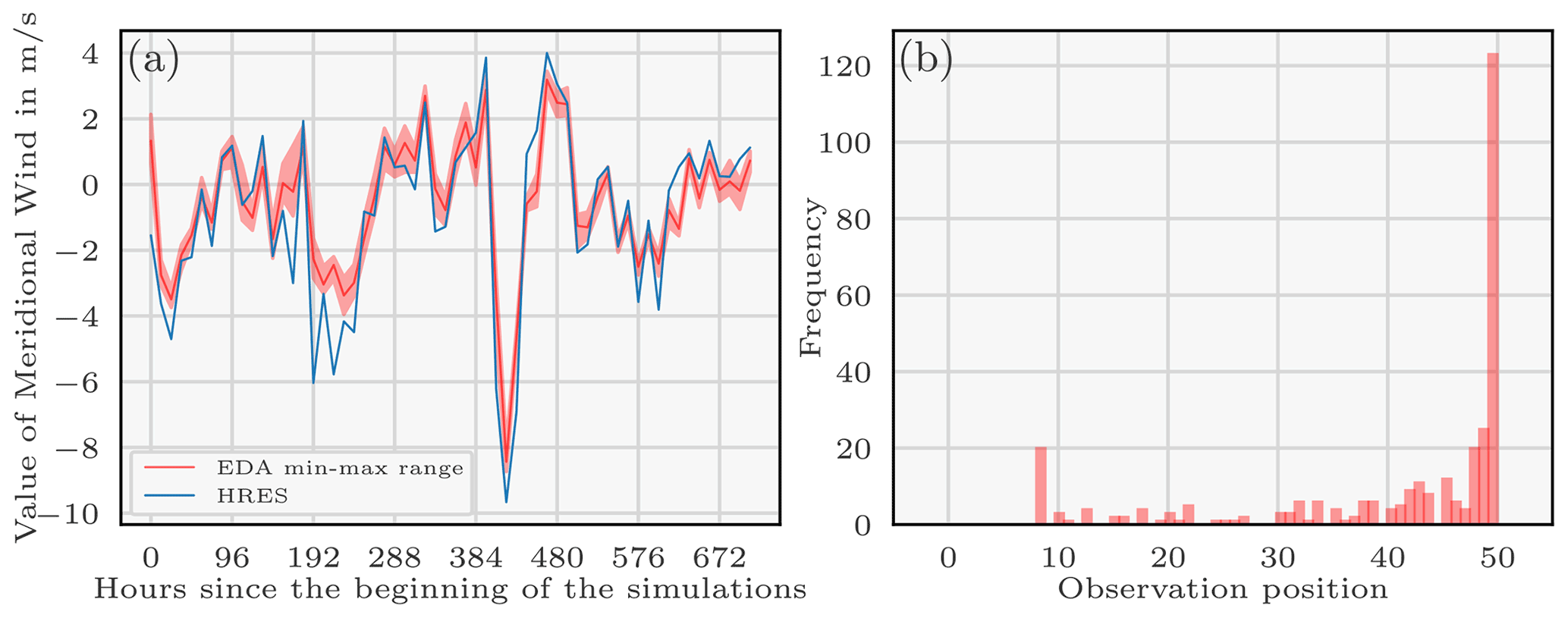
Figure 6Evolution of the meridional wind of the HRES and EDA meteorologies for a random location in Europe since the beginning of the simulations. The red curve represents the mean of the meridional wind EDA members with the space between the minimum and maximum values (a). Rank histogram: comparison between the 106Ru observations and the reference predictions of the enhanced ensemble (b).
Figures 4a, b and 5a show the marginal pdfs of the variables describing the source using the observation-sorting algorithm and for several likelihoods, using the HRES meteorology. The longitude pdf support ranges from 59 to 60.75∘ E, and the latitude support from 55.75 to 56.75∘ N. The extent of the joined coordinates pdfs is slightly greater than the extent of any coordinate pdf reconstructed using any likelihood distribution. Nevertheless, they are in general all consistent in the pointed area of 106Ru release, especially given that the observation operators interpolation step is 0.5∘.
The daily total retrieved released activity (TRRA) was mostly significant on 25 September. The extent of the release pdf overlap is smaller than the coordinates pdf overlap extent; probable TRRA values range from 140 to 300 TBq.
This shows that using a single likelihood is not enough to aggregate the whole uncertainty of the problem. Furthermore, we can see on these graphs that the threshold choice of the likelihood also has a moderate impact on the final coordinate pdfs and an important impact on the TRRA pdfs. More precisely, the daily TRRA pdfs obtained from the log-normal and the log-Laplace choices are moderately impacted by the threshold value choice.
Figures 4c, d and 5b show the marginal pdfs of the variables describing the source in the same configuration, except that nine error variances are used and assigned to the observations using the spatial clustering. The impact of this clustering is not significant: pdfs of the coordinates or the TRRA do not change meaningfully with the use of this representation of the R covariance matrix. Diverse trials for numbers of centroids between 3 and 9 have been carried out and all yield similar results.
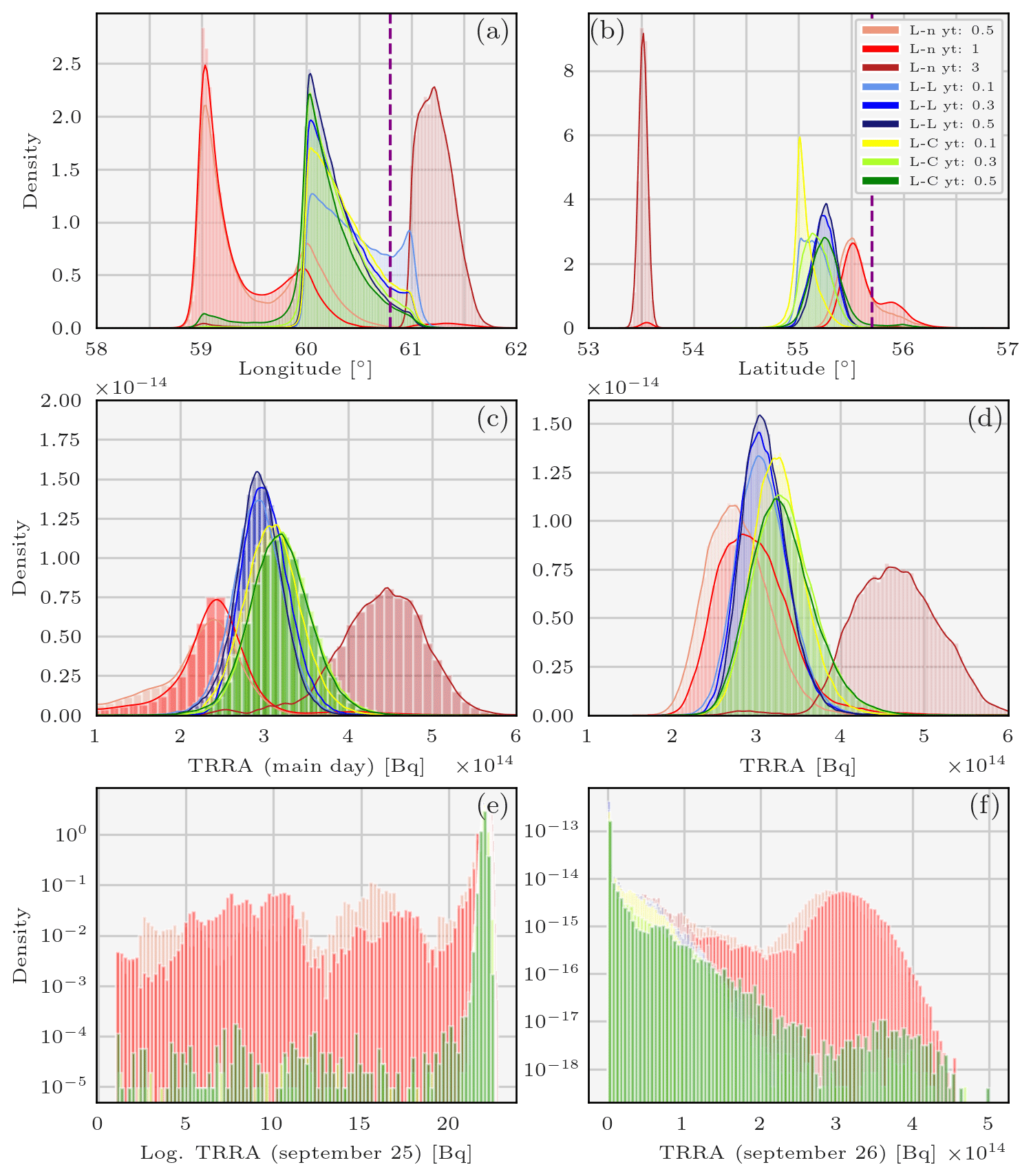
Figure 7Pdfs of the variables describing the 106Ru source sampled using the parallel tempering method and the enhanced ensemble of observation operators and the observation-sorting algorithm and for various likelihoods: longitude (a), latitude (b), TRRA on the main day (c), TRRA (d), log. TRRA on 25 September (e) and TRRA on 26 September (f). L-L means log-Laplace, L-n means log-normal, L-C means log-Cauchy, and yt is the likelihood threshold.
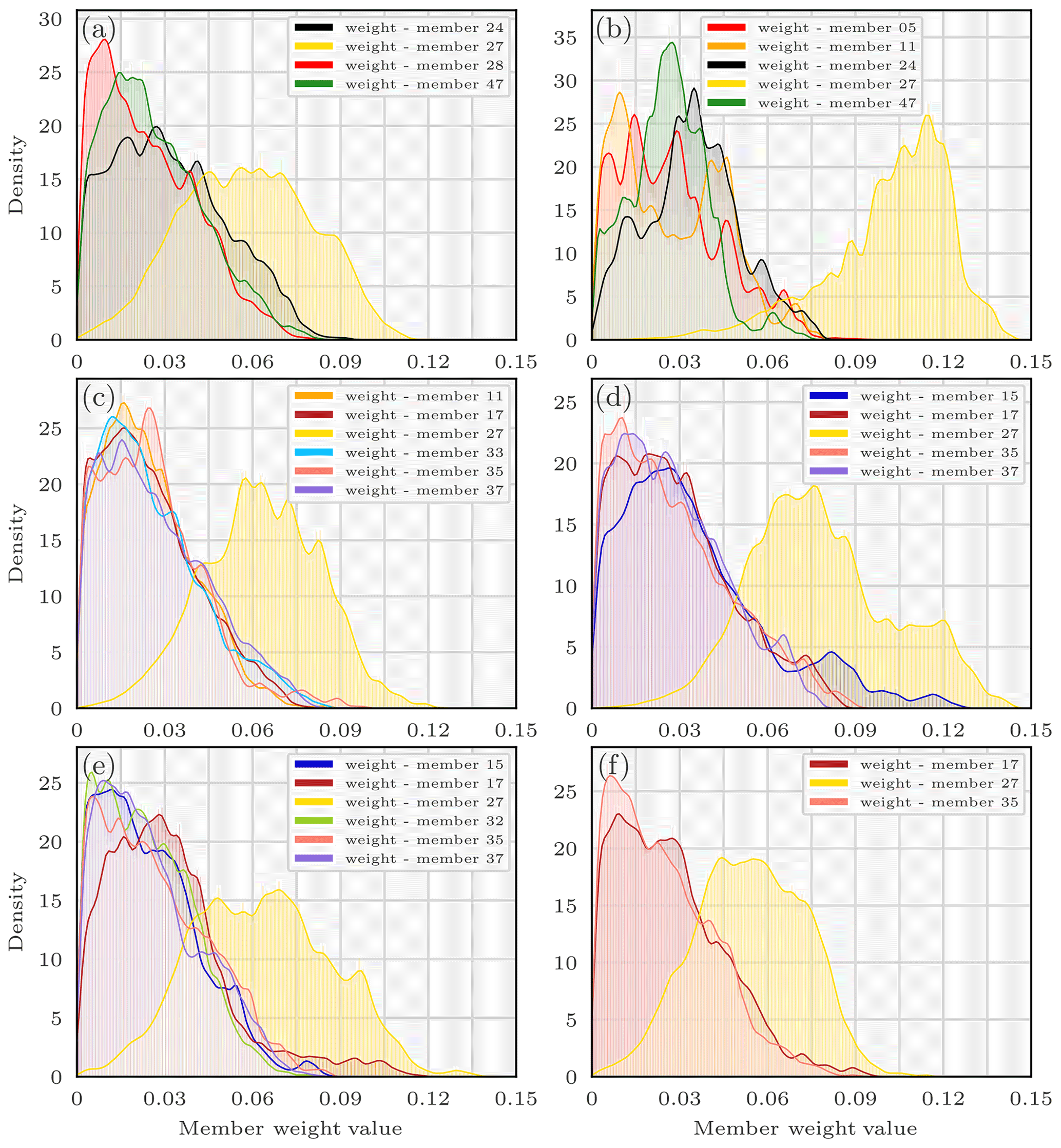
Figure 8Densities of the weights of the members of the enhanced ensemble using the parallel tempering method and the observation-sorting algorithm for diverse likelihoods: log-normal with threshold 0.5 (a), log-normal with threshold 3 (b), log-Laplace with threshold 0.1 (c), log-Laplace with threshold 0.5 (d), log-Cauchy with threshold 0.1 (e), log-Cauchy with threshold 0.3 (f). L-L means log-Laplace, L-n means log-normal, L-C means log-Cauchy, and yt is the likelihood threshold. Only densities with high medians are shown.
3.3.4 Sampling from the enhanced ensemble with weight interpolation
Before reconstructing the pdfs of the 106Ru source using the observation operator ensemble, we study the dispersion of this enhanced ensemble, created by sampling on the transport model parameters and the ERA5 EDA. A number of 50 members are used to create the enhanced ensemble.
The original ERA5 EDA meteorology is under-dispersive as can be seen in Fig. 6a: in blue is drawn the HRES meridional wind predictions, and in red the EDA meridional wind mean prediction with the maximum and minimum values, for a random location in Europe. For most of the times, the ensemble values do not even recover the HRES value, which indicates that the ensemble has a small dispersion. ECMWF ensemble forecasts indeed tend to be under-dispersive in the boundary layer (especially in the short range) (Pinson and Hagedorn, 2011; Leadbetter et al., 2020). Furthermore, the release height parameter has low chances to be of significant impact. Therefore, with only two variables (Kz and dry deposition velocity) with high chances to be of significant impact to sample, we consider that 50 members is an adequate number.
To examine the spread of the ensemble of observation operators, we need to define a reference source xref for which predictions of the ensemble can be computed for each member and compared afterwards with the 106Ru observations. Note that the reference source choice is necessarily an arbitrary choice which biases the results. We use the most probable source from Saunier et al. (2019) as the reference source: the reference source is located in [60,55] and with a release of 90 TBq on 25 September and of 166 TBq on 26 September. The corresponding rank diagram (Fig. 6b) shows that the predictions often underestimate the observation value. A ROC and a reliability diagram are provided in Appendix C to study more deeply the ensemble of observation operators.
We now study the impact of adding meteorological and transport uncertainties into the sampling process: . The integration of an enhanced ensemble to deal with the meteorological and dispersion uncertainties has a very interesting impact on the reconstruction of the source variables. In combination with the use of diverse likelihoods, pdfs of the longitude and latitude are significantly impacted as can be seen in Fig. 7a and b. The longitude pdf support ranges from 58.75 to 61.2∘ E, and the latitude support ranges from 54.75 to 56.5∘ N, not considering the results with the log-normal likelihood of threshold 3 mBq m−3. The “outlier” distribution reconstructed with the log-normal likelihood of threshold 3 mBq m−3 is indeed questionable, as it differs widely from all the others. The threshold of 3 mBq m−3 was chosen as an upper bound and does not seem to be the most appropriate choice. In Fig. 7d, the joint TRRA distribution (where joint means considering all likelihoods) ranges from 150–200 to 450–500 TBq, not considering the “outlier” reconstruction. The variance of the joint enhanced ensemble TRRA is therefore bigger than the variance of the joint HRES TRRA which ranged from 140 to 300 TBq. This means that the uncertainty emanating from meteorological data and the transport model is better quantified. Note also that with the log-normal likelihood and a threshold of 0.5 mBq m−3, or 1 mBq m−3, or log-Cauchy with a threshold of 0.3 or 0.5 mBq m−3, the release is split between the 25th and the 26th as can be noted in Fig. 7e and f. In other words, the integration of weights member interpolation adds uncertainty not only over the magnitude of the release but also over the timing of the release (here, the day).
The pdfs of the member weights are displayed in Fig. 8 for several likelihoods and thresholds. Only weight pdfs with high medians are included in the graphs for the sake of visibility. Member 27 is always included in the combination of weights which define the interpolated observation operator used to make the predictions and is often one of the most important or the most important part of this combination. Since the ERA5 EDA is not very dispersive, we can make the hypothesis that the weight density of a member mainly depends on the dispersion parameters which are used for creating this member (or observation operator). The height layer of the release for the operator member 27 is mainly the one between 40 and 120 m (>90 %), its deposition constant velocity is which is very close to the lower bound (minimal possible deposit), and the Kz has been multiplied by 0.47. It also corresponds to member 6 of the ERA5 EDA.
Member 17 is present 4 times and corresponds to a deposition velocity of , a release mainly on the second layer (75 %), and a Kz multiplied by 1.32. Member 35 is present 4 times and corresponds to a deposition velocity of , a release mainly on the first layer (83 %), and a Kz multiplied by 0.45. Two hypotheses can be made: the weight of member 27 is large because it has a very small deposition velocity, and that deposition velocity is overestimated when using the standard choice. Second, Kz may be overestimated, since the members 27 and 35 are built out of a small multiplicator on the Kz.
These conclusions must, however, be largely qualified and are mainly proposed to present the interest and potential of the method.
In this paper, we proposed several methods to quantify the uncertainties in the assessment of a radionuclide atmospheric source. In the first step, the impact of the choice of the likelihood which largely defines the a posteriori distribution when the chosen priors are non-informative was examined. Several likelihoods were selected from a list of criteria: log-normal, log-Laplace, and log-Cauchy distributions which quantify the fit between observations and predictions.
In the second step, we have focused on the likelihood covariance matrix R which measures the observation and modelling uncertainties. A method has been proposed to model this covariance matrix from a sorting of the observations into two groups, discriminant and non-discriminant, to avoid observations with low discrimination power to artificially decrease the spread of the posterior distributions.
Finally, in order to incorporate the uncertainties related to the meteorological fields and the transport model into the sampling process, ensemble methods have been implemented. An ensemble of observation operators, constructed from the ERA5 ECMWF EDA and a perturbation of the IRSN ldX transport model dry deposition, release height, and vertical turbulent diffusion coefficient parameters, was used in place of a deterministic observation operator. Following a Bayesian approach, each operator of the ensemble was given a weight which was sampled in the MCMC algorithm.
Thereafter, a full reconstruction of the variables describing the source of the 106Ru in September 2017 and their uncertainty was provided, and the merits of these different methods have been demonstrated, improving each time the quantification of uncertainties.
First, the refinement of R according to the relevance criterion of the observations has been demonstrated following an application of parallel tempering. Due to the use of the sorting algorithm, the standard deviation of the density of the reconstructed longitude in a certain configuration was multiplied by two. In practice, the sorting algorithm avoids an underestimation of the observation error variance.
Second, independent MCMC samplings with the three likelihoods examined performed with the HRES meteorological fields showed that the support of the TRRA distribution was moderately impacted by the choice of the likelihood. This reveals that the uncertainties are not correctly estimated when using a single likelihood.
Finally, incorporating the uncertainties of the meteorological and transport fields using the observation operator set in combination with the use of multiple likelihoods had a significant impact on the conditional distribution of the TRRA, increasing the magnitude and timing of the release variances, but also on the conditional distribution of the release source coordinates. We have also shown that this method allows the reconstruction of transport model parameters such as dry deposition velocity or release height.
With the help of the three main methods proposed in this paper, the longitude spread of the 106Ru source lies in between 59 and 61∘ E, and the latitude spread between 55 and 56∘ N. The total release is estimated to be between 200 and 450 TBq and peaked mainly on 25 September (although a release on 26 September cannot be neglected).
We recommend the use of all three methods when sampling sources of atmospheric releases: all three methods can have a moderate to large effect depending on the event modelling (e.g. the use of three likelihoods has a large effect only in combination with the inclusion of physical uncertainties). As far as the likelihood is concerned, we think that the log-Cauchy distribution is the most suitable while the choice of the associated threshold necessarily depends on the observations. We intend to apply the methods to the Fukushima–Daiichi accident.
Let us suppose that the cost function is computed from a Gaussian likelihood; then we have
Suppose we add to this set of observations y of size Nobs a second set of observations of size for which the corresponding predictions are also zero. This can happen for instance if we add observations preceding the accident.
If we take into account this new set of observations, the cost function becomes
since for each observation of the new set, . Suppose now that goes to infinity; then the observation error variance r should tend to 0. As r→0, the distributions sampled are being more and more peaked.
Therefore in this configuration, adding a given number of observations anterior to the accident will degrade the distributions of the source variables. This problem is due to the homogeneous and hence inconsistent design of the observation error covariance matrix. Assigning a different r to this new set of observations would solve effectively this false paradox.
We compare a first model (0) where only one variable r is used to describe the covariance matrix R and a second model (d) where two variables r1 et r2 are describing R with the AIC (Hastie et al., 2009). Therefore
where L(0) and L(d) are the maximum likelihoods when using the first and second model respectively. Using Gaussian likelihoods to facilitate calculations and out of normalisation constants,
where and N1 and N2 are the number of observations assigned to the first and second model, respectively (). Therefore, comparing the max likelihoods of the two models,
We can note that the smaller S2 (and therefore the bigger S1), the better the model (d) compared to (0). The observation-sorting algorithm specifically aims at selecting a large set of observations (the non-discriminant observations ynd) with a very small maximum likelihood S2=Snd.
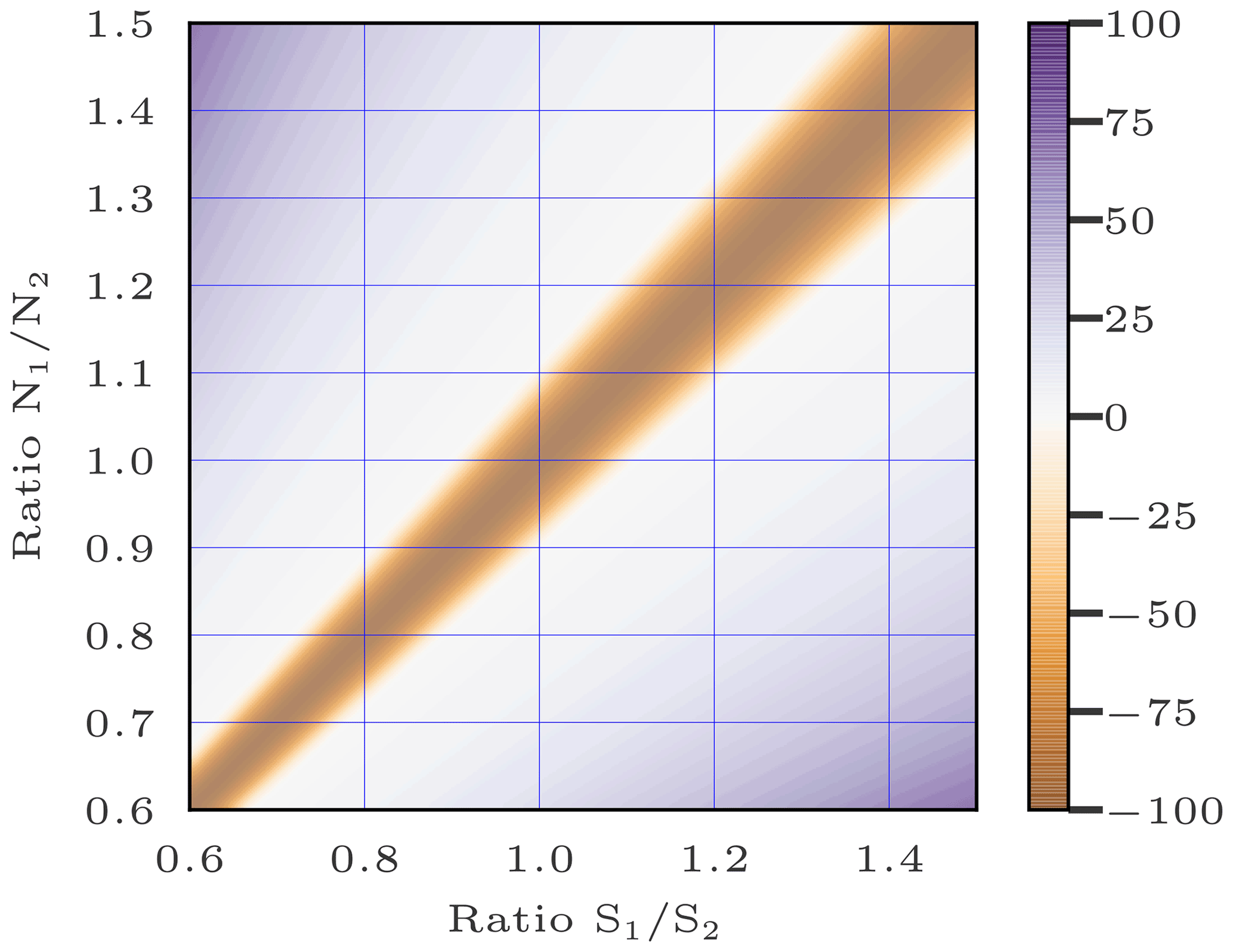
Figure B1AIC(0) − AIC(d) with negative values multiplied by 100 to be more visible. Negative values indicate the cases where the model (0) with one variable is preferable. Positives values indicate the cases where the model (d) with two variables is preferable. On the x axis is the ratio between the likelihoods S1 and S2 linked to variables 1 and 2, respectively, of the model (d). On the y axis is the ratio between the numbers of observations N1 and N2 linked to variables 1 and 2, respectively, of the model (d).
We write and and use ; then
and we can draw AIC(0) − AIC(d).
According to the AIC criterion, the model (d) with two variables is judged useless if the average likelihood of the observations y1 linked to group 1 is close to the average likelihood of the observations y2 linked to group 2. The observation-sorting algorithm specifically aims at creating two groups of observations: one where the average likelihood of the observations is close to 0 and another one where the average likelihood of the observations is high. In other words, the ratio () tends towards infinity (depending on the choice of ϵd) and the ratio (), for example, is equal to 1. That is, the sorting algorithm creates two groups such that the corresponding coordinates () and () in Fig. B1 are as far away from negative values as possible. Therefore, the AIC criterion totally justifies the need for the clustering accomplished by the observation-sorting algorithm.
A ROC and a reliability diagram are computed using the reference source defined in Sect. 3.3.4 to assess the ability of the forecast to discriminate between events and non-events and its reliability, respectively (Delle Monache et al., 2006). A good ROC curve is as close as possible to 1 in probability of a hit and to 0 in probability of a false occurrence. We recall that a hit for a certain threshold t is when the observation belongs to the considered interval and a number of corresponding predictions greater than the threshold t belong to the considered interval. A false occurrence is when the observation does not belong to the considered interval but a number of corresponding predictions greater than the threshold t belong to the considered interval. The ROC is plotted for a list of thresholds t.
Each curve of Fig. C1a and b corresponds to a dichotomous event: where y is an observation, and ymin and ymax are the values that define whether the event is true or false for y. These indicators are plotted for several ranges [ymin,ymax]. A reliable ensemble, for a given event, has a reliability curve as close as possible to the identity function.
From the ROC curves, the enhanced ensemble appears to be good for discriminating: curves always have a low rate of false occurrence and an acceptable hit rate. In the reliability diagrams, the forecast overestimates the probability that an observation is between 0 and 20 mBq m−3 which relates to predictions underestimating the observations in general. For the three other events, the diagrams show an acceptable reliability in the enhanced forecast.

Figure C1ROC curve and reliability diagram of the enhanced ensemble created with sampling of EDA and the transport model parameters.
The observation dataset used is described in detail and is publicly available in the work of Masson et al. (2019) (https://doi.org/10.1073/pnas.1907571116) as Supplement.
JDLB designed the software, contributed to the construction of the methodology and conceptualisation, performed the investigations, and wrote the original version of the paper. MB supervised the work and contributed to the construction of the methodology, conceptualisation, and the revision/edition of the manuscript. OS supervised the work, provided resources and contributed to the construction of the methodology, conceptualisation, and the revision/edition of the manuscript. YR contributed to the construction of the methodology and the revision/edition of the manuscript.
The authors declare that they have no conflict of interest.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The authors are grateful to the European Centre for Medium-Range Weather Forecasts (ECMWF) for the ERA5 meteorological fields used in this study. They also wish to thank Didier Lucor, Yann Richet and Anne Mathieu for their comments on this work. CEREA is a member of Institut Pierre Simon Laplace (IPSL). The authors would like to thank the reviewers for their many constructive comments.
This paper was edited by Yun Qian and reviewed by Pieter De Meutter, Ondřej Tichý, and three anonymous referees.
Abida, R. and Bocquet, M.: Targeting of observations for accidental atmospheric release monitoring, Atmos. Environ., 43, 6312–6327, https://doi.org/10.1016/j.atmosenv.2009.09.029, 2009. a
Anderson, J. L.: A Method for Producing and Evaluating Probabilistic Forecasts from Ensemble Model Integrations, J. Climate, 9, 1518–1530, https://doi.org/10.1175/1520-0442(1996)009<1518:AMFPAE>2.0.CO;2, 1996. a
Atchadé, Y. F., Roberts, G. O., and Rosenthal, J. S.: Towards optimal scaling of metropolis-coupled Markov chain Monte Carlo, Stat. Comput., 21, 555–568, https://doi.org/10.1007/s11222-010-9192-1, 2011. a
Baklanov, A. and Sørensen, J. H.: Parameterisation of radionuclide deposition in atmospheric long-range transport modelling, Phys. Chem. Earth Pt. B, 26, 787–799, https://doi.org/10.1016/S1464-1909(01)00087-9, 2001. a
Baragatti, M.: Sélection bayésienne de variables et méthodes de type Parallel Tempering avec et sans vraisemblance, Thèse de doctorat, Aix-Marseille 2, 2011. a
Bardsley, J., Solonen, A., Haario, H., and Laine, M.: Randomize-Then-Optimize: A Method for Sampling from Posterior Distributions in Nonlinear Inverse Problems, SIAM J. Sci. Comput., 36, A1895–A1910, https://doi.org/10.1137/140964023, 2014. a
Bocquet, M.: Parameter-field estimation for atmospheric dispersion: application to the Chernobyl accident using 4D-Var, Q. J. Roy. Meteor. Soc., 138, 664–681, https://doi.org/10.1002/qj.961, 2012. a
Chow, F. K., Kosović, B., and Chan, S.: Source Inversion for Contaminant Plume Dispersion in Urban Environments Using Building-Resolving Simulations, J. Appl. Meteorol.,Clim., 47, 1553–1572, https://doi.org/10.1175/2007JAMC1733.1, 2008. a
De Meutter, P. and Hoffman, I.: Bayesian source reconstruction of an anomalous Selenium-75 release at a nuclear research institute, J. Environ. Radioactiv., 218, 106225, https://doi.org/10.1016/j.jenvrad.2020.106225, 2020. a
De Meutter, P., Hoffman, I., and Ungar, K.: On the model uncertainties in Bayesian source reconstruction using an ensemble of weather predictions, the emission inverse modelling system FREAR v1.0, and the Lagrangian transport and dispersion model Flexpart v9.0.2, Geosci. Model Dev., 14, 1237–1252, https://doi.org/10.5194/gmd-14-1237-2021, 2021. a
Delle Monache, L. and Stull, R. B.: An ensemble air-quality forecast over western Europe during an ozone episode, Atmos. Environ., 37, 3469–3474, https://doi.org/10.1016/S1352-2310(03)00475-8, 2003. a
Delle Monache, L., Hacker, J. P., Zhou, Y., Deng, X., and Stull, R. B.: Probabilistic aspects of meteorological and ozone regional ensemble forecasts, J. Geophys. Res., 111, D24307, https://doi.org/10.1029/2005JD006917, 2006. a, b
Delle Monache, L., Lundquist, J., Kosović, B., Johannesson, G., Dyer, K., Aines, R. D., Chow, F., Belles, R., Hanley, W., Larsen, S., Loosmore, G., Nitao, J., Sugiyama, G., and Vogt, P.: Bayesian inference and markov chain monte carlo sampling to reconstruct a contaminant source on a continental scale, J. Appl. Meteorol. Clim., 47, 2600–2613, https://doi.org/10.1175/2008JAMC1766.1, 2008. a, b, c
Dumont Le Brazidec, J., Bocquet, M., Saunier, O., and Roustan, Y.: MCMC methods applied to the reconstruction of the autumn 2017 Ruthenium-106 atmospheric contamination source, Atmos. Environ. X, 6, 100071, https://doi.org/10.1016/j.aeaoa.2020.100071, 2020. a, b, c, d, e, f, g, h, i, j, k, l
Earl, D. J. and Deem, M. W.: Parallel tempering: Theory, applications, and new perspectives, Phys. Chem. Chem. Phys., 7, 3910, https://doi.org/10.1039/b509983h, 2005. a
Girard, S., Korsakissok, I., and Mallet, V.: Screening sensitivity analysis of a radionuclides atmospheric dispersion model applied to the Fukushima disaster, Atmos. Environ., 95, 490–500, https://doi.org/10.1016/j.atmosenv.2014.07.010, 2014. a, b
Hastie, T., Tibshirani, R., and Friedman, J.: The Elements of Statistical Learning: Data Mining, Inference, and Prediction, Springer Series in Statistics, Springer-Verlag, New York, 2 edn., 2009. a
Hersbach, H., Bell, B., Berrisford, P., Hirahara, S., Horányi, A., Muñoz Sabater, J., Nicolas, J., Peubey, C., Radu, R., Schepers, D., Simmons, A., Soci, C., Abdalla, S., Abellan, X., Balsamo, G., Bechtold, P., Biavati, G., Bidlot, J., Bonavita, M., Chiara, G. D., Dahlgren, P., Dee, D., Diamantakis, M., Dragani, R., Flemming, J., Forbes, R., Fuentes, M., Geer, A., Haimberger, L., Healy, S., Hogan, R. J., Hólm, E., Janisková, M., Keeley, S., Laloyaux, P., Lopez, P., Lupu, C., Radnoti, G., Rosnay, P. d., Rozum, I., Vamborg, F., Villaume, S., and Thépaut, J.-N.: The ERA5 global reanalysis, Q. J. Roy. Meteor. Soc., 146, 1999–2049, https://doi.org/10.1002/qj.3803, 2020. a
Keats, A., Yee, E., and Lien, F.-S.: Bayesian inference for source determination with applications to a complex urban environment, Atmos. Environ., 41, 465–479, https://doi.org/10.1016/j.atmosenv.2006.08.044, 2007. a
Kovalets, I. V., Romanenko, O., and Synkevych, R.: Adaptation of the RODOS system for analysis of possible sources of Ru-106 detected in 2017, J. Environ. Radioactiv., 220–221, 106302, https://doi.org/10.1016/j.jenvrad.2020.106302, 2020. a
Leadbetter, S. J., Andronopoulos, S., Bedwell, P., Chevalier-Jabet, K., Geertsema, G., Gering, F., Hamburger, T., Jones, A. R., Klein, H., Korsakissok, I., Mathieu, A., Pázmándi, T., Périllat, R., Rudas, C., Sogachev, A., Szántó, P., Tomas, J. M., Twenhöfel, C., Vries, H. d., and Wellings, J.: Ranking uncertainties in atmospheric dispersion modelling following the accidental release of radioactive material, Radioprotection, 55, S51–S55, https://doi.org/10.1051/radiopro/2020012, 2020. a
Leith, C. E.: Theoretical Skill of Monte Carlo Forecasts, Mon. Weather Rev., 102, 409–418, https://doi.org/10.1175/1520-0493(1974)102<0409:TSOMCF>2.0.CO;2, 1974. a
Liu, Y., Haussaire, J.-M., Bocquet, M., Roustan, Y., Saunier, O., and Mathieu, A.: Uncertainty quantification of pollutant source retrieval: comparison of Bayesian methods with application to the Chernobyl and Fukushima Daiichi accidental releases of radionuclides, Q. J. Roy. Meteor. Soc., 143, 2886–2901, https://doi.org/10.1002/qj.3138, 2017. a, b, c, d
Louis, J.-F.: A parametric model of vertical eddy fluxes in the atmosphere, Bound.-Lay. Meteorol., 17, 187–202, https://doi.org/10.1007/BF00117978, 1979. a
Mallet, V.: Ensemble forecast of analyses: Coupling data assimilation and sequential aggregation, J. Geophys. Res.-Atmos., 115, D24303, https://doi.org/10.1029/2010JD014259, 2010. a
Mallet, V. and Sportisse, B.: Ensemble-based air quality forecasts: A multimodel approach applied to ozone, J. Geophys. Res.-Atmos., 111, D18302, https://doi.org/10.1029/2005JD006675, 2006. a
Mallet, V., Stoltz, G., and Mauricette, B.: Ozone ensemble forecast with machine learning algorithms, J. Geophys. Res.-Atmos., 114, D05307, https://doi.org/10.1029/2008JD009978, 2009. a
Masson, O., Steinhauser, G., Zok, D., Saunier, O., Angelov, H., Babić, D., Bečková, V., Bieringer, J., Bruggeman, M., Burbidge, C. I., Conil, S., Dalheimer, A., De Geer, L.-E., de Vismes Ott, A., Eleftheriadis, K., Estier, S., Fischer, H., Garavaglia, M. G., Gasco Leonarte, C., Gorzkiewicz, K., Hainz, D., Hoffman, I., Hýža, M., Isajenko, K., Karhunen, T., Kastlander, J., Katzlberger, C., Kierepko, R., Knetsch, G.-J., Kövendiné Kónyi, J., Lecomte, M., Mietelski, J. W., Min, P., Møller, B., Nielsen, S. P., Nikolic, J., Nikolovska, L., Penev, I., Petrinec, B., Povinec, P. P., Querfeld, R., Raimondi, O., Ransby, D., Ringer, W., Romanenko, O., Rusconi, R., Saey, P. R. J., Samsonov, V., Šilobritienė, B., Simion, E., Söderström, C., Šoštarić, M., Steinkopff, T., Steinmann, P., Sýkora, I., Tabachnyi, L., Todorovic, D., Tomankiewicz, E., Tschiersch, J., Tsibranski, R., Tzortzis, M., Ungar, K., Vidic, A., Weller, A., Wershofen, H., Zagyvai, P., Zalewska, T., Zapata García, D., and Zorko, B.: Airborne concentrations and chemical considerations of radioactive ruthenium from an undeclared major nuclear release in 2017 [data set], P. Natl. Acad. Sci. USA, 116, 16750, https://doi.org/10.1073/pnas.1907571116, 2019. a, b
McDonald, J. B.: Some Generalized Functions for the Size Distribution of Income, in: Modeling Income Distributions and Lorenz Curves, edited by: Chotikapanich, D., Economic Studies in Equality, Social Exclusion and Well-Being, pp. 37–55, Springer, New York, NY, https://doi.org/10.1007/978-0-387-72796-7_3, 2008. a, b
Pinson, P. and Hagedorn, R.: Verification of the ECMWF ensemble forecasts of wind speed against observations, December 2012, Meteorological Applications, 19, 484–500, https://doi.org/10.21957/r7h9hxu9k, 2011. a
Quélo, D., Krysta, M., Bocquet, M., Isnard, O., Minier, Y., and Sportisse, B.: Validation of the Polyphemus platform on the ETEX, Chernobyl and Algeciras cases, Atmos. Environ., 41, 5300–5315, https://doi.org/10.1016/j.atmosenv.2007.02.035, 2007. a
Rajaona, H., Septier, F., Armand, P., Delignon, Y., Olry, C., Albergel, A., and Moussafir, J.: An adaptive bayesian inference algorithm to estimate the parameters of a hazardous atmospheric release, Atmos. Environ., 122, 748–762, https://doi.org/10.1016/j.atmosenv.2015.10.026, 2015. a, b, c, d
Satchell, S. and Knight, J.: Return Distributions in Finance, Elsevier Monographs, Elsevier, https://doi.org/10.1016/B978-0-7506-4751-9.X5000-0, 2000. a, b
Sato, Y., Takigawa, M., Sekiyama, T. T., Kajino, M., Terada, H., Nagai, H., Kondo, H., Uchida, J., Goto, D., Quélo, D., Mathieu, A., Quérel, A., Fang, S., Morino, Y., Schoenberg, P. v., Grahn, H., Brännström, N., Hirao, S., Tsuruta, H., Yamazawa, H., and Nakajima, T.: Model Intercomparison of Atmospheric 137Cs From the Fukushima Daiichi Nuclear Power Plant Accident: Simulations Based on Identical Input Data, J. Geophys. Res.-Atmos., 123, 11748–11765, https://doi.org/10.1029/2018JD029144, 2018. a
Saunier, O., Mathieu, A., Didier, D., Tombette, M., Quélo, D., Winiarek, V., and Bocquet, M.: An inverse modeling method to assess the source term of the Fukushima Nuclear Power Plant accident using gamma dose rate observations, Atmos. Chem. Phys., 13, 11403–11421, https://doi.org/10.5194/acp-13-11403-2013, 2013. a, b, c, d
Saunier, O., Didier, D., Mathieu, A., Masson, O., and Dumont Le Brazidec, J.: Atmospheric modeling and source reconstruction of radioactive ruthenium from an undeclared major release in 2017, P. Natl. Acad. Sci. USA, 116, 24991, https://doi.org/10.1073/pnas.1907823116, 2019. a, b, c, d, e, f
Senocak, I., Hengartner, N. W., Short, M. B., and Daniel, W. B.: Stochastic event reconstruction of atmospheric contaminant dispersion using Bayesian inference, Atmos. Environ., 42, 7718–7727, https://doi.org/10.1016/j.atmosenv.2008.05.024, 2008. a
Swendsen, R. H. and Wang, J.-S.: Replica Monte Carlo simulation of spin glasses, Phys. Rev. Lett., 57, 2607–2609, https://doi.org/10.1103/PhysRevLett.57.2607, 1986. a
Tichý, O., Šmídl, V., Hofman, R., and Stohl, A.: LS-APC v1.0: a tuning-free method for the linear inverse problem and its application to source-term determination, Geosci. Model Dev., 9, 4297–4311, https://doi.org/10.5194/gmd-9-4297-2016, 2016. a, b, c
Tichý, O., Hýža, M., Evangeliou, N., and Šmídl, V.: Real-time measurement of radionuclide concentrations and its impact on inverse modeling of 106Ru release in the fall of 2017, Atmos. Meas. Tech., 14, 803–818, https://doi.org/10.5194/amt-14-803-2021, 2021. a
Tombette, M., Quentric, E., Quélo, D., Benoit, J., Mathieu, A., Korsakissok, I., and Didier, D.: C3X: a software platform for assessing the consequences of an accidental release of radioactivity into the atmosphere, Poster Presented at Fourth European IRPA Congress, pp. 23–27, 2014. a
Troen, I. B. and Mahrt, L.: A simple model of the atmospheric boundary layer; sensitivity to surface evaporation, Bound.-Lay. Meteorol., 37, 129–148, https://doi.org/10.1007/BF00122760, 1986. a
Wang, Y., Huang, H., Huang, L., and Ristic, B.: Evaluation of Bayesian source estimation methods with Prairie Grass observations and Gaussian plume model: A comparison of likelihood functions and distance measures, Atmos. Environ., 152, 519–530, https://doi.org/10.1016/j.atmosenv.2017.01.014, 2017. a
Western, L. M., Millington, S. C., Benfield-Dexter, A., and Witham, C. S.: Source estimation of an unexpected release of Ruthenium-106 in 2017 using an inverse modelling approach, J. Environ. Radioactiv., 220–221, 106304, https://doi.org/10.1016/j.jenvrad.2020.106304, 2020. a
Winiarek, V., Bocquet, M., Saunier, O., and Mathieu, A.: Estimation of errors in the inverse modeling of accidental release of atmospheric pollutant: Application to the reconstruction of the cesium-137 and iodine-131 source terms from the Fukushima Daiichi power plant, J. Geophys. Res.-Atmos., 117, D05122, https://doi.org/10.1029/2011JD016932, 2012. a, b
Winiarek, V., Bocquet, M., Duhanyan, N., Roustan, Y., Saunier, O., and Mathieu, A.: Estimation of the caesium-137 source term from the Fukushima Daiichi nuclear power plant using a consistent joint assimilation of air concentration and deposition observations, Atmos. Environ., 82, 268–279, https://doi.org/10.1016/j.atmosenv.2013.10.017, 2014. a
Yee, E.: Theory for Reconstruction of an Unknown Number of Contaminant Sources using Probabilistic Inference, Bound.-Lay. Meteorol., 127, 359–394, https://doi.org/10.1007/s10546-008-9270-5, 2008. a
Yee, E., Hoffman, I., and Ungar, K.: Bayesian Inference for Source Reconstruction: A Real-World Application, International Scholarly Research Notices, 2014, 507634, https://doi.org/10.1155/2014/507634, 2014. a, b
- Abstract
- Introduction
- Evaluating uncertainties in the Bayesian inverse problem
- Airborne radioactivity increase in Europe in autumn 2017
- Summary and conclusions
- Appendix A: False paradox of the discriminant and non-discriminant observations
- Appendix B: Study of the observation-sorting algorithm clustering with the Akaike information criterion (AIC)
- Appendix C: ROC and reliability diagram of the observation operators ensemble
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Review statement
- References
- Abstract
- Introduction
- Evaluating uncertainties in the Bayesian inverse problem
- Airborne radioactivity increase in Europe in autumn 2017
- Summary and conclusions
- Appendix A: False paradox of the discriminant and non-discriminant observations
- Appendix B: Study of the observation-sorting algorithm clustering with the Akaike information criterion (AIC)
- Appendix C: ROC and reliability diagram of the observation operators ensemble
- Data availability
- Author contributions
- Competing interests
- Disclaimer
- Acknowledgements
- Review statement
- References