the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 14 Oct 2022
| 14 Oct 2022
Spatiotemporal continuous estimates of daily 1 km PM2.5 from 2000 to present under the Tracking Air Pollution in China (TAP) framework
Qingyang Xiao
Shigan Liu
Jiajun Liu
Qiang Zhang
High spatial resolution PM2.5 data covering a long time period are urgently needed to support population exposure assessment and refined air quality management. In this study, we provided complete-coverage PM2.5 predictions with a 1 km spatial resolution from 2000 to the present under the Tracking Air Pollution in China (TAP, http://tapdata.org.cn/, last access: 3 October 2022) framework. To support high spatial resolution modeling, we collected PM2.5 measurements from both national and local monitoring stations. To correctly reflect the temporal variations in land cover characteristics that affected the local variations in PM2.5, we constructed continuous annual geoinformation datasets, including the road maps and ensemble gridded population maps, in China from 2000 to 2021. We also examined various model structures and predictor combinations to balance the computational cost and model performance. The final model fused 10 km TAP PM2.5 predictions from our previous work, 1 km satellite aerosol optical depth retrievals, and land use parameters with a random forest model. Our annual model had an out-of-bag R2 ranging between 0.80 and 0.84, and our hindcast model had a by-year cross-validation R2 of 0.76. This open-access, 1 km resolution PM2.5 data product, with complete coverage, successfully revealed the local-scale spatial variations in PM2.5 and could benefit environmental studies and policymaking.
- Article
(13272 KB) - Full-text XML
-
Supplement
(875 KB) - BibTeX
- EndNote





Air pollution has been a non-negligible environmental problem around the world. China implemented strict clean air policies in the past decade that considerably improved air quality. To support the policy evaluation and air quality management, we constructed the Tracking Air Pollution in China (TAP) platform (http://tapdata.org.cn/, last access: 3 October 2022), which provides a near real-time distribution of air pollutants – i.e., PM2.5 and O3 – at a 0.1∘ (approximately 10 km) spatial resolution, from the fusion of ground measurements, satellite retrievals, and chemical transport model (CTM) simulations (Geng et al., 2021). The TAP data benefited the evaluations of clean air policies and the characterization of air pollution exposure (Xiao et al., 2020, 2021b, c). However, with the improved air pollution control targets that require refined air quality management, the detailed monitoring of air pollution distribution at higher spatial resolutions is urgently needed.
Recent developments in machine learning algorithms and remote sensing techniques have fueled the production of air pollution data at high spatiotemporal resolutions. For example, moderate-resolution imaging spectroradiometer (MODIS) products provide aerosol optical depth (AOD) retrievals at a 3 km resolution, contributing to the prediction of ground-level PM2.5 concentrations at the local scale (Xie et al., 2015; He and Huang, 2018; Hu et al., 2019). The multiangle implementation of atmospheric correction (MAIAC) algorithm provides AOD retrievals at a 1 km resolution and benefits predictions of PM2.5 distribution at a 1 km (Wei et al., 2021; Goldberg et al., 2019; Xiao et al., 2017; Bai et al., 2022b) or higher spatial resolution (Huang et al., 2021). Recently, with the Gaofen-5 satellite retrieval, Zhang et al. (2018) predicted the PM2.5 concentration at a 160 m resolution. However, most of these high-resolution data products are limited to after 2013 or cover a specific region of China. Few studies have filled the missing predictions that have resulted from missing satellite retrievals (Bai et al., 2022b; Ma et al., 2022). This discontinuous PM2.5 prediction in space and time not only limits the application of PM2.5 products in scientific research and environmental management but also biases the characterization of population exposure to PM2.5 pollution (Xiao et al., 2017). Additionally, although high-resolution PM2.5 prediction models widely included various land use data, e.g., road maps, land cover types, and points of interest (POIs), to describe the local-scale spatial variations in air pollution emissions and air pollution levels, most studies used only 1 or 2 years of land use data during the whole study period and ignored the critical variations in them. This lack of temporal variations in land use data may affect the spatial accuracy of high-resolution PM2.5 predictions.
In this study, we constructed a high-resolution PM2.5 concentration prediction system under the TAP framework in order to provide 1 km resolution full-coverage PM2.5 retrievals covering a long time period. To correctly reveal the spatial characteristics of PM2.5 distribution at such a high spatial resolution, we processed MAIAC satellite retrievals as well as evaluated and constructed various temporally continuous land use parameters with statistical and geospatial modeling that have not been included in previous TAP models. By fusing high-resolution MAIAC satellite retrievals, TAP PM2.5 products at a 10 km resolution, satellite normalized difference vegetation index (NDVI) products, and various continuous long-term land use data, we provide 1 km resolution PM2.5 predictions from 2000 to the present, with complete coverage and timely updates. The high quality and easy accessibility of our high-resolution PM2.5 data could support research on air pollution and environmental health at local scales and contribute to the management of local air quality.
The workflow of this study is shown in Fig. 1. First, we processed and assimilated various predictors. The daily-scale varying predictors include satellite retrieval, TAP 10 km PM2.5 predictions, and meteorological fields, and the land use variables include road maps, population distribution, artificial impervious area, and vegetation index. In China, the high-speed economic development in the past several decades has led to significant changes in land use and population distribution. To correctly reveal the temporal variations in land use parameters and further benefit the description of local-scale PM2.5 concentration variations, we constructed temporally continuous land use predictors through statistical and spatial modeling. We then optimized the model structure and selected model predictors through various examinations to balance the model performance and computing cost. With the selected model design, we fitted three models under the TAP framework: the hindcast model, with training data from 2013 to 2020 to predict historical PM2.5 concentrations from 2000 to 2014; the annual model, with training data of each corresponding year from 2015 to 2020; and the near real-time model, with rolling 1-year training data that provides near real-time PM2.5 predictions until the day before present day.
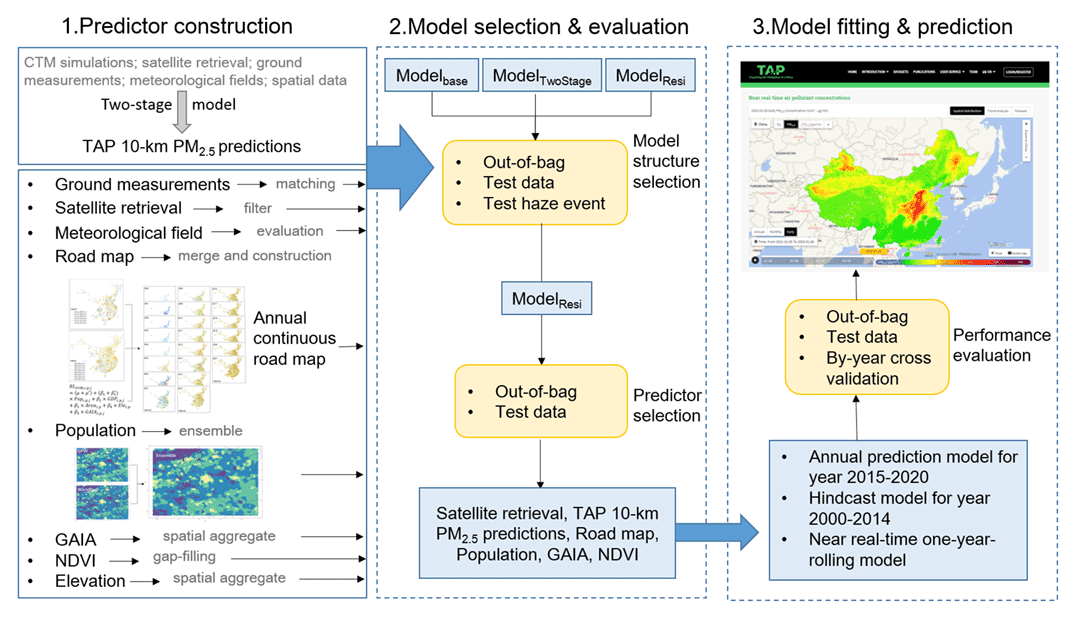
Figure 1Workflow of this study.
2.1 Ground measurements of PM2.5
The hourly PM2.5 measurements from national air quality monitoring stations were downloaded from the China National Environmental Monitoring Center (http://www.cnemc.cn/, last access: 3 October 2022). To examine the model's prediction ability in space, we also collected PM2.5 measurements from local air quality monitoring stations operated by local government agencies (Fig. S1 in the Supplement). The hourly PM2.5 concentration measurements below 1 µg m−3, the lowest measurement limit of most monitors, and above 2000 µg m−3 were excluded for quality control of measurements. Identical continuous hourly measurements found within at least 3 h of each other were also removed. Daily average PM2.5 concentration data generated with fewer than 18 hourly measurements were removed.
In order to examine whether the quality of the measurements from national monitors and from regional monitors is comparable, we matched the nearest national and regional monitors to compare their measurements. Specifically, we selected such national–regional monitor pairs with a distance of less than 0.5∘ between them and compared their daily average PM2.5 measurements. This comparison illustrates that measurements from regional monitors matched well with measurements from the nearest national monitors, with the linear regression coefficient of determination (R2) of 0.89 (slope of 0.99 and intercept of 1.00). The average difference between daily matched regional and national measurements is 1.6 µg m−3.
2.2 Full-coverage PM2.5 predictions at a 10 km resolution
The 10 km resolution PM2.5 predictions, which were estimated from a two-stage machine learning modeling system, were downloaded from the TAP website (http://tapdata.org.cn/, last access: 3 October 2022) (Xiao et al., 2021c). Previous evaluations reported that the PM2.5 prediction model with the out-of-bag (OOB) R2 (the R2 of the linear regression between measurements and predictions from trees that did not include these measurements for training) ranged between 0.80 and 0.88 (Geng et al., 2021). These TAP PM2.5 data at a 10 km resolution with complete coverage are updated in near real-time.
2.3 MAIAC retrievals
The multi-angle implementation of atmospheric correction (MAIAC) (Lyapustin et al., 2011a, b) data were downloaded from the NASA Earthdata site (https://lpdaac.usgs.gov/products/mcd19a2v006/, last access: 3 October 2022). Only pixels with high-quality retrievals were included (QA. CloudMask=clear and QA. AdjacencyMask=clear) (Kloog et al., 2015; Lyapustin, 2018). Since the Aqua and Terra satellites cross over at around 10:30 and 13:30 local time respectively, the daily spatial missing patterns of Aqua and Terra AOD retrievals are different. To improve the coverage of AOD, we fitted daily linear regressions between Aqua AOD and Terra AOD (Eqs. 1–2). Then we predicted the missing AOD of one satellite when the AOD of another satellite exists. After the daily linear interpolation, the Aqua and Terra AODs were averaged to reflect the daily aerosol loadings.
where and represent the Aqua and Terra AOD of grid g on day i, respectively. μi and βi represent the intercept and slope on day i, respectively.
2.4 Meteorological fields and evaluation
Various reanalysis data products, including ERA5, MERRA-2, and GEOS-FP, have been used to provide meteorological files in previous air pollution prediction models (Geng et al., 2021; Wei et al., 2021; Xiao et al., 2017). In this study, to select the best-performing meteorological data with long temporal data coverage (from 2000 to the present) and timely updating, we evaluated ERA5-Land, ERA5, and MERRA-2 meteorological datasets with meteorological measurements at regional air quality monitoring stations during 2019. The evaluation results showed that ERA5-Land data at a 0.1∘ resolution outperformed the MERRA-2 reanalysis data and the ERA5 reanalysis data (Table S1 in the Supplement). We extracted and processed the ERA5-Land parameters – including 2 m temperature, 10 m u and v components of wind, surface pressure, and total precipitation – for model predictor selection. The 2 m relative humidity was calculated from the 2 m temperature and the 2 m dew point temperature.
2.5 Construction of the time series of land use variables
2.5.1 Population density
We evaluated and fused various global gridded population density data that were publicly available, including the LandScan Global Population Database from 2000 to 2019 (Dobson et al., 2000); the Gridded Population of the World (GPW) data product (version 4) for 2000, 2005, 2010, 2015, and 2020 (Doxsey-Whitfield et al., 2015); and the annual WorldPop data at a 1 km resolution from 2000–2020 (Wardrop et al., 2018; Reed et al., 2018). We linearly interpolated the GPW data for each year. For data quality evaluation, we obtained the sum population at the county or city level from 2000 to 2019 from the China City Yearbooks. The gridded population datasets were aggregated to county or city sums and compared to the yearbook records. The LandScan data outperformed the other two datasets (Fig. S2); however, the spatial distributions of the LandScan data showed an unreasonable pattern and were excluded. As shown in Fig. S4, the LandScan data present very high population density along the road and many randomly distributed, high-population grids in certain square areas on the map. Due to the significant spatial variations in data accuracy (Bai et al., 2018; Wang et al., 2011), we fused the GPW and WorldPop data to improve data quality across space. We first fitted linear regressions between the gridded population and yearbook records of each county or city that had at least six matched data pairs. Then, we averaged the gridded population with the R2 as a weight (Eq. 3). We selected the R2 rather than the root mean square error (RMSE) as the weight, because the spatial variation trends were more important than the number of populations in the prediction of PM2.5.
where Popi,y represents the ensemble population of grid g in the county or city i of year y; GPWg(i),y and WorldPopg(i),y represent the population of grid g, year y of dataset GPW and WorldPop, respectively; and and represent R2 of GPW and WorldPop in the county or city i.
For counties or cities that did not have sufficient matched data pairs for regression fitting, we employed the weight of the nearest county or city for the ensemble (Fig. S3). We subsequently constrained the city level and national sum population to be consistent with the record from the China City Statistical Yearbook and the China Statistical Yearbook.
2.5.2 Land cover
The percentage of artificial impervious area of each 1 km modeling grid was calculated from the annual global artificial impervious area (GAIA) data at a 30 m resolution from 2000 to 2018 (http://data.ess.tsinghua.edu.cn/gaia.html, last access: 15 March 2022). To estimate the GAIA distribution after 2018, we fitted linear regressions with data from 2016 to 2018 for each grid and extrapolated the GAIA values of 2019, 2020, and 2021. The data from 2013 to 2017 were used to evaluate the performance of this linear extrapolation. The examination results comparing the GAIA data and the first-year, second-year, and third-year extrapolated GAIA predictions showed that the R2 values ranged from 0.996 to 0.999, 0.985 to 0.989, and 0.969 to 0.979, respectively.
2.5.3 Road map
Limited road maps are available in China. We collected the annual road maps from 2013 to the present from OpenStreetMap (https://www.openstreetmap.org, last access: 3 October 2022) (Barrington-Leigh and Millard-Ball, 2017), a crowdsourced, collaborative geographic information collection project. OpenStreetMap data have been widely used for road density analysis and the construction of world road data products (Zhang et al., 2015; Meijer et al., 2018). A previous evaluation study reported on the considerable accuracy of the OpenStreetMap data (Haklay, 2010). To evaluate the quality of the OpenStreetMap data and to fill the historical data gap before 2013, we also collected the road maps of 2000, 2004, 2005, 2010, 2012, 2014, and 2015 from the survey.
We first extracted the length of various types of roads from the OpenStreetMap data and from the road survey at the grid level. We combined some road types to make the road classification more comparable in OpenStreetMap and in the survey (Table S2). To estimate the annual road distribution before 2013, we first compared the grid-level road length of 2014 extracted from OpenStreetMap and the survey map (Table S3). Then, we modified the survey map data to construct the OpenStreetMap-type gridded road length of the years that the survey map data were available using the equation listed below:
where represents the OpenStreetMap-type road length of year j over grid i, and RLroad,j represents the survey-type road length of year j over grid i.
After estimating the OpenStreetMap-type road length of years when the survey maps were available, we filled the gap years by weighted linear interpolation. First, we estimated the city-level sum road length of different road types by a linear mixed effects model (LME) (Meijer et al., 2018):
where represents the sum road length of city c in province p of year j; μ represents the fixed intercept, and μ′ represents the province-level random intercept; β1, β2, β3, β4, and β5 represent the fixed slope of the city's average population density, per capita gross domestic product (GDP), city area, city average elevation, and city average GAIA; represents the province-level random slope of population density. The log 10 transformation was conducted for all the continuous variables to account for the skewed distribution (Meijer et al., 2018). Stepwise linear regression was used to select the significant predictors (Meijer et al., 2018). To evaluate the LME model performance, by-year cross-validation and 4-year cross-validation were conducted. Regarding the by-year cross-validation, we selected 1-year's data for model testing in sequence and used the data of the remaining years for model training. Regarding the 4-year cross-validation, we selected 2013, 2014, and 2015 for model testing in sequence and used the data from 4 years after the corresponding testing year for model fitting. For example, when selecting 2013 for model testing, the data from 2017, 2018, and 2019 were used to fit the model.
After estimating the city-level sum road length, we further used the sum road length as a weight to assign the road length changes to each gap year. The equation is listed below:
where and represent the road length over grid i of the starting and ending year with available OSM-type road data, respectively; and represent the road length of city c of the starting and ending year with available OSM-type road data, respectively; and represent the road length of city c of the gap year j.
2.6 Other auxiliary datasets
We downloaded the monthly Terra MODIS NDVI (MOD13A3) at a 1 km resolution and filled the missing NDVI data by the nearest neighbor spatial smoothing approach. The average elevation data at a 30 m resolution were extracted from the Advanced Spaceborne Thermal Emission and Reflection Radiometer (ASTER) Global Digital Elevation Model (GDEM) version 2.
2.7 Data assimilation
All the predictors were assimilated to the 1 km MAIAC pixels by various geostatistical methods. The meteorological data and PM2.5 predictions at a 0.1∘ resolution were downscaled to the 1 km MAIAC pixels with the inverse distance weighting method. The elevation pixels falling in each 1 km grid cell were averaged. The NDVI data were assigned to the MAIAC pixels by the nearest neighbor method.
2.8 Optimization and evaluation of the prediction model
To make the PM2.5 prediction process efficient and highly accurate, we designed various examinations to optimize the model structure and identify key predictors of the PM2.5 prediction system.
Three model structures were evaluated: modelTwoStage has a two-stage design, with the first-stage model predicting the high pollution indicator and the second-stage model predicting the residual between 10 km TAP PM2.5 predictions and measurements (Xiao et al., 2021c); modelResi is a one-stage model that predicts the residual between 10 km TAP PM2.5 predictions and measurements; and modelBase is a one-stage model that directly predicts the PM2.5 concentration with the 10 km TAP PM2.5 prediction as a predictor. Since the underestimation of high pollution events are widely reported, in addition to the evaluations including all the test measurements, we conducted additional evaluations focusing on the prediction accuracy of haze events when the daily average PM2.5 concentration was higher than the 75 µg m−3 national secondary air quality standard.
Then, we selected the critical predictors of the PM2.5 prediction model (Fig. 1). We first constructed the full model with all the predictors, and then we removed the meteorological predictors in sequence, according to the importance of parameters estimated from the full model. Predictors with the smallest importance were removed first. Data from 2019 were used for model predictor optimization.
Various statistics were employed to characterize model performance. The OOB predictions, which predicted the measurements by trees that were trained with randomly selected samples excluding these measurements, were provided during the training of the random forest. Comparing the OOB predictions with measurements in linear regression provided us with the OOB R2, the RMSE, and the mean prediction error (MPE). To evaluate the model's ability to reveal PM2.5 variations at the local scale and at locations without monitoring, we used the measurements from national stations for model training and the measurements from the high-density local stations from model evaluation. These local stations are primarily located in Hebei, Henan, Shandong, and Chengdu (Fig. S1). The evaluation results of OOB and with test data were used to optimize the model structure and select predictors. Then, to evaluate the optimized final model's prediction ability in time, we conducted a by-year cross-validation.
Consistent with the previous TAP PM2.5 prediction framework, the missing satellite AOD retrievals were filled by adjusting the first layer of the decision tree and setting the availability status of AOD as the cutoff point of the first layer of the decision trees. The performance of this gap-filling method has been fully evaluated in our previous studies (Xiao et al., 2021a; Geng et al., 2021).
3.1 Temporal variations in predictors
The high-resolution PM2.5 prediction was supported by various high-resolution predictors. In addition to the 1 km resolution MAIAC AOD, we also constructed and presented various 1 km resolution predictors, including road maps, population distribution, artificial impervious area, and NDVI (Fig. 2).
We evaluated the road length model for various road types through by-year cross-validation and 4-year cross-validation (Table S4). The cross-validation predictions of all road types were highly correlated with the OSM data. The 4-year cross-validation performance were comparable to the by-year cross-validation performance, indicating that the model's temporal prediction ability was robust. The performance of the secondary road model was slightly better than that of the highway model and primary road model, showing higher correlations between local socioeconomic factors and secondary road length relative to highways and primary roads that are constructed nationally. The predicted highway length correctly revealed the temporal trends of the records of highway length from the China traffic yearbooks, with correlation coefficients of 0.99. Since the road type classifications of the OSM and China traffic yearbooks are inconsistent, we did not compare the lengths of other types of roads. We observed a consistent increasing trend in road length for all road types across China (Fig. 2). The predicted road maps also displayed the construction of some local landmarks, e.g., the 6th Ring Road in Beijing.
Compared to the statistical yearbook records, our ensemble population data showed R2 and RMSE values of 0.74 and 0.19 million, respectively, outperforming other gridded population data (Fig. S5). The changes in population density distribution were inconsistent across China due to the substantial internal migration during the past decades (Fig. 2). For example, we observed that the high-speed economic development in Shenzhen city and the whole Pearl River Delta (PRD) attracted a large migration population, but the populations in small cities in Northeast and Central China were consistent or decreasing. The artificial impervious area also increased significantly across China, especially in regions with fast economic development. The consistent increase in NDVI over most parts of China, especially in the southeast, showed the achievement of environmental protection in China. We found considerable missingness in MAIAC retrievals over China, especially in the southeast and northeast regions with large populations. Thus, gap-filling is necessary to provide valuable PM2.5 predictions across China.
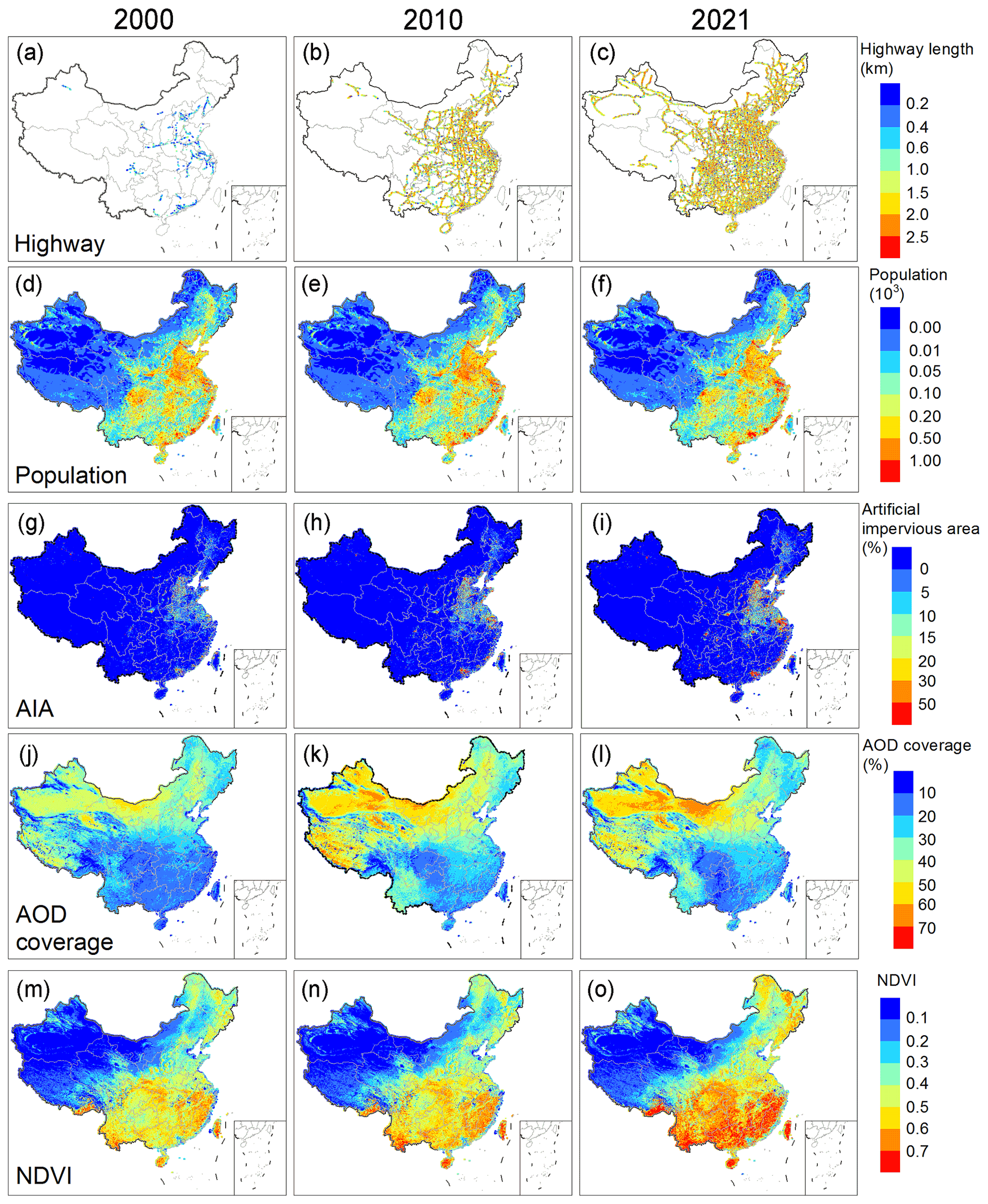
Figure 2Estimated annual distributions of key predictors – including highway length (a–c), population (d–f), artificial impervious area (g–i), MAIAC AOD coverage (j–l), and normalized difference vegetation index (NDVI) (m–o) – in 2000, 2010, and 2021 across China.
3.2 Optimization of the high-resolution PM2.5 prediction model
Three model structures – modelTwoStage, modelResi, and modelBase – were examined in this study. The evaluation results showed that these candidate models performed comparably in R2 in all the evaluations (Fig. 3). However, the modelBase that directly predicts the measurements showed significantly larger prediction error than the other two models during haze events. For some years – e.g., 2017 and 2018 – the average prediction error of the modelBase was more than double the prediction errors of modelTwoStage and modelResi. This result was consistent with our previous findings that the prediction of residuals enlarges the response of the dependent variable to the predictors, thus benefiting the prediction of extreme events (Xiao et al., 2021c). We did not observe significant differences between modelTwoStage and modelResi. Thus, considering the prediction performance and the model-fitting time expense, the modelResi was selected.
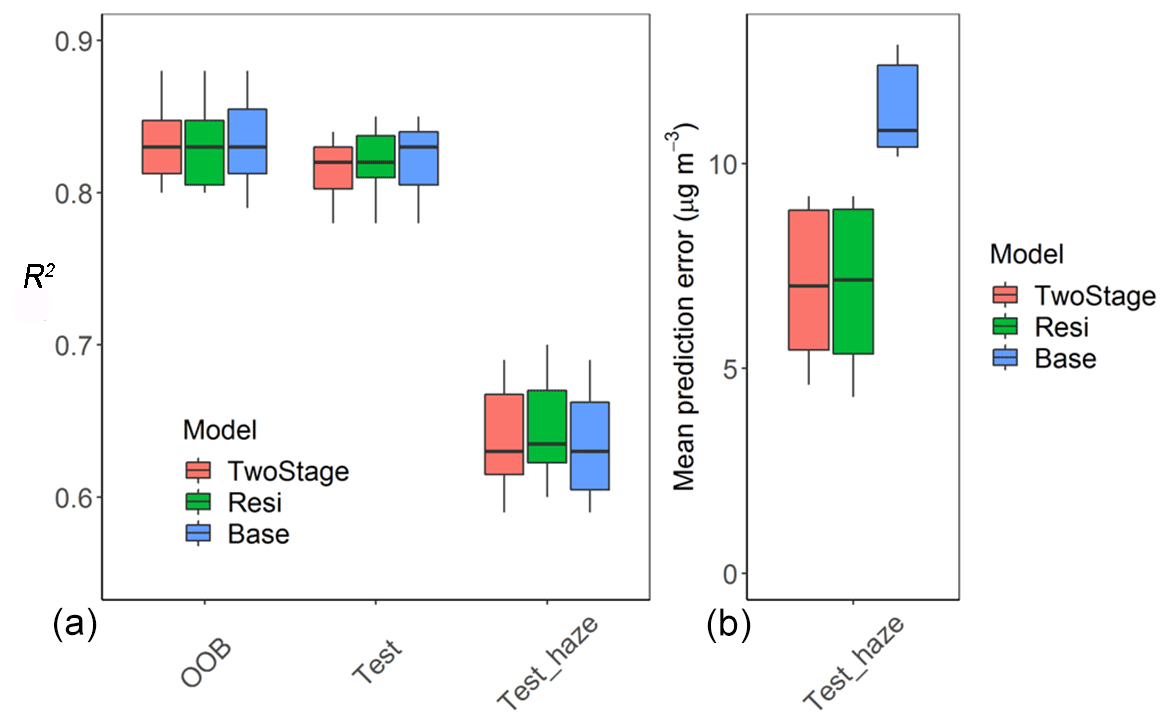
Figure 3The performance of modelTwoStage, modelResi, and modelBase in the out-of-bag evaluation (OOB), the evaluation with test data from local stations (Test), and the evaluation with test data higher than 75 µg m−3 (Test_haze). (a) The evaluation R2; (b) the average prediction error.
We then examined the contribution of meteorological fields to the high-resolution PM2.5 prediction (Table S5). Compared to the full model, the OOB R2 of the model without meteorological fields decreased from 0.85 to 0.80; however, the R2 with test data decreased by only 0.02, from 0.85 to 0.83. This evaluation showed that the contribution of meteorological fields to high-resolution PM2.5 predictions was limited. Potential reasons include the coarse resolution of the meteorological data limiting the characterization of high-resolution variations in meteorological fields or in PM2.5 distributions. Additionally, the meteorological effects on PM2.5 have been considered in the 0.1∘ PM2.5 data that served as a predictor in the model. Comprehensively considering the model performance and the meteorological data update frequency, we removed meteorological fields.
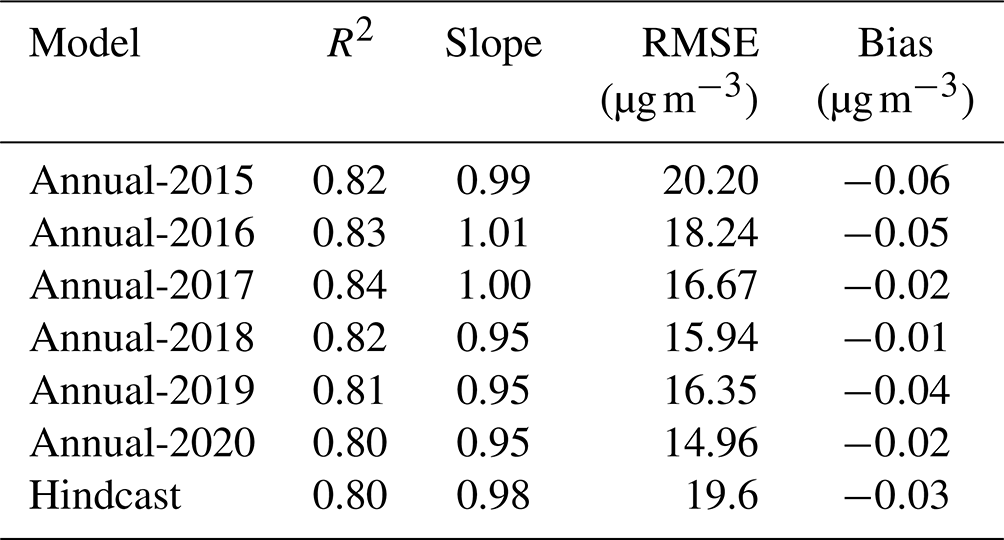
Table 1 summarizes the OOB performance of our final annual models and hindcast model. The model R2 ranged between 0.80 and 0.84 for annual models. The small interannual variations indicated that our model was robust and provided predictions with constant quality during the study period. The very small model mean prediction error (bias) together with the slopes close to 1 showed the inexistence of systemic bias in the prediction models. Our model performance was comparable with previous studies (Huang et al., 2021; Wei et al., 2019, 2020, 2021). The high-cast model performed comparably in the OOB evaluation, the test data evaluation, and the by-year cross-validation evaluation (Fig. 4), showing great accuracy and high robustness. No considerable overfitting was observed, and no system bias was detected in the spatial prediction (test data) and temporal prediction (by-year cross-validation) examinations.
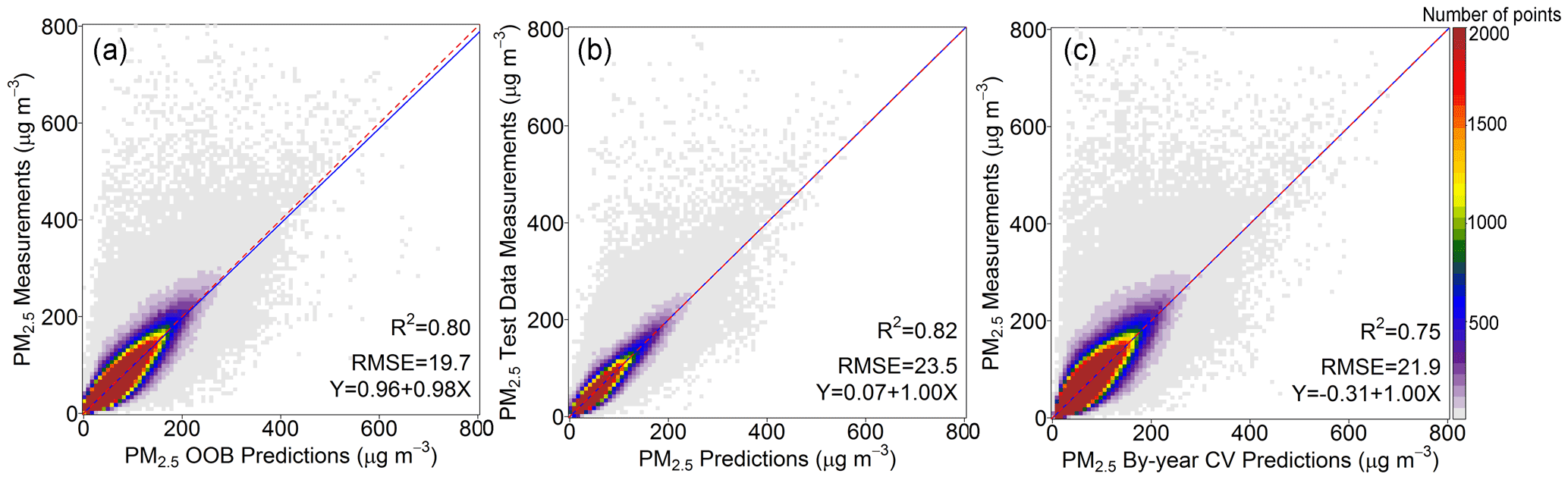
Figure 4Model performance of the hindcast model trained with all the data from 2013 to 2019. (a) Evaluation with out-of-bag predictions; (b) evaluation with test data; (c) evaluation with by-year cross-validation predictions.
Table 1Out-of-bag performance of the annual model trained with all data of each year and the hindcast model trained with all data during 2013–2019.
3.3 The spatiotemporal characteristics of the high-resolution PM2.5 map
The high-resolution PM2.5 maps revealed critical local patterns of annual (Figs. 5–6) and daily (Figs. 7–8) pollution distributions that could not be identified by the 0.1∘ resolution maps. Comparing the daily population weighted average PM2.5 concentrations from 2000 to 2021, the number of days with PM2.5 higher than 75 µg m−3 were significantly reduced after 2013 across China (Fig. 5). Beijing–Tianjin–Hebei (BTH) showed high pollution levels with the haze days that occurred across the year. In recent years, benefiting from the pollution control policies, high pollution days in BTH outside of winter were basically removed. The annual maps of PM2.5 distribution in 2000 showed that the most polluted regions were located in Beijing, Hebei, and north of Henan; in 2007 and 2013, the highly polluted regions extended and covered BTH, Shandong, Shanxi, Hunan, the Sichuan Basin, and the Yangtze River Delta (YRD). After 2013, with the strict pollution control policies, the air quality across China was significantly improved, and the polluted regions shrank in 2021.
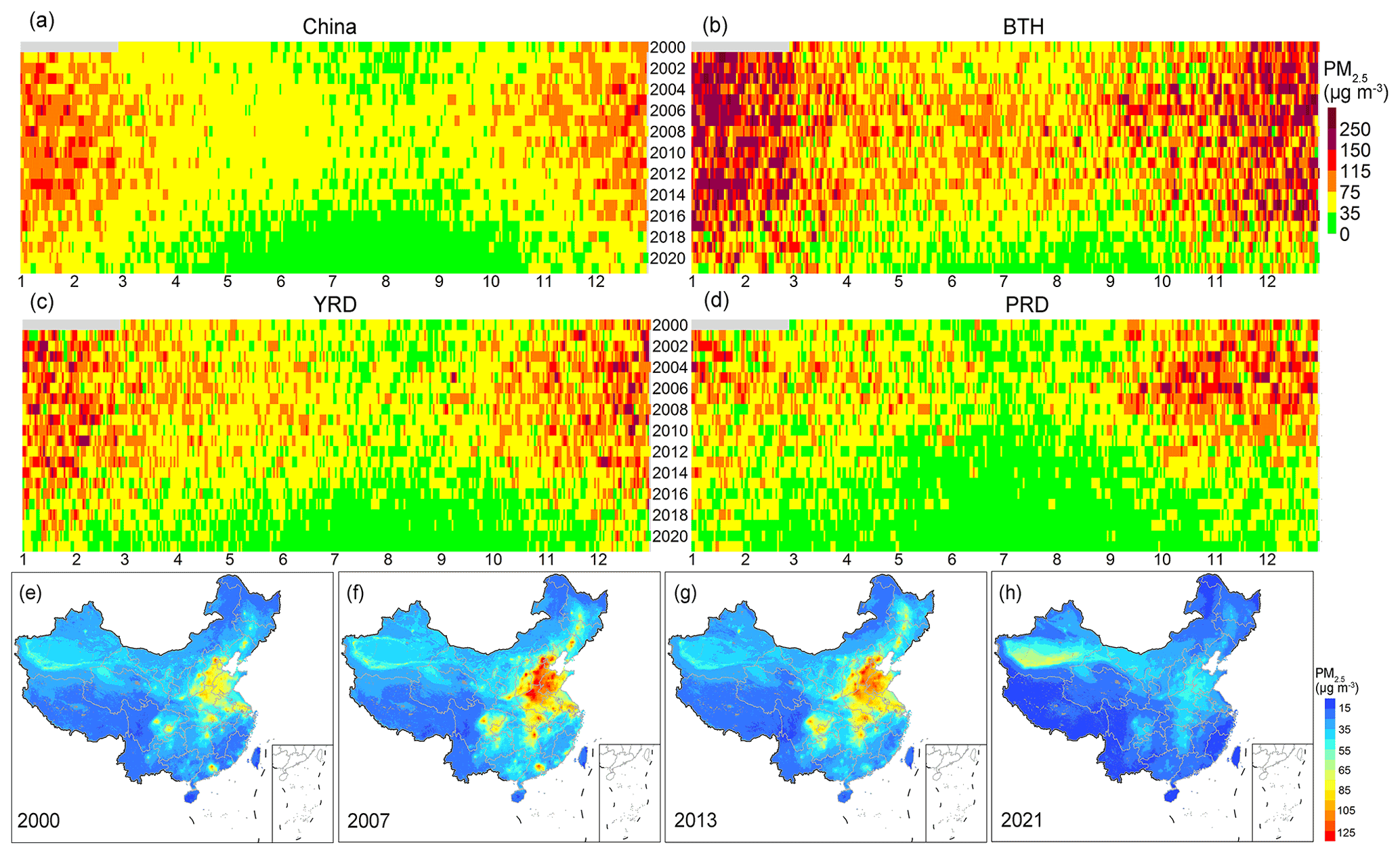
Figure 5Temporal variations of the daily population-weighted PM2.5 cover over (a) China, (b) Beijing–Tianjin–Hebei (BTH), (c) Yangtze River Delta (YRD), and (d) Pearl River Delta (PRD) as well as the annual average PM2.5 distribution in (e) 2000, (f) 2007, (g) 2013, (h) 2021.
Figure 6 highlighted the variations in spatial distribution of PM2.5 at the local scale. We compared the annual PM2.5 anomaly, which is the gridded PM2.5 minus the regional average PM2.5, in 2013 and 2021 in YRD. The pollution hotspots transferred from the city centers with monitors to rural regions with limited monitoring. We found that, after 2013, although the percent of days and counties with population-weighted PM2.5 that violates the primary (35 µg m−3) and secondary air quality standard is continuously decreasing, the percent of days and counties with rural-county pollution higher than urban-county pollution significantly increased. In 2013, more than half of the days and counties showed higher pollution in urban counties than in rural counties when the PM2.5 was greater than 35 µg m−3; however, in 2021, more than 96 % of these pollution days and counties showed lower pollution in urban counties than in rural counties. In 2017 and 2020, all the days with PM2.5 greater than 75 µg m−3 showed higher rural-county pollution than urban-county pollution. One reason for the transportation of pollution hotspots is that the PM2.5 reduction during 2013–2021 was much greater in city centers than in rural regions. In 2021, most regional high pollution hotspots were transferred to around the junction of cities or towns.
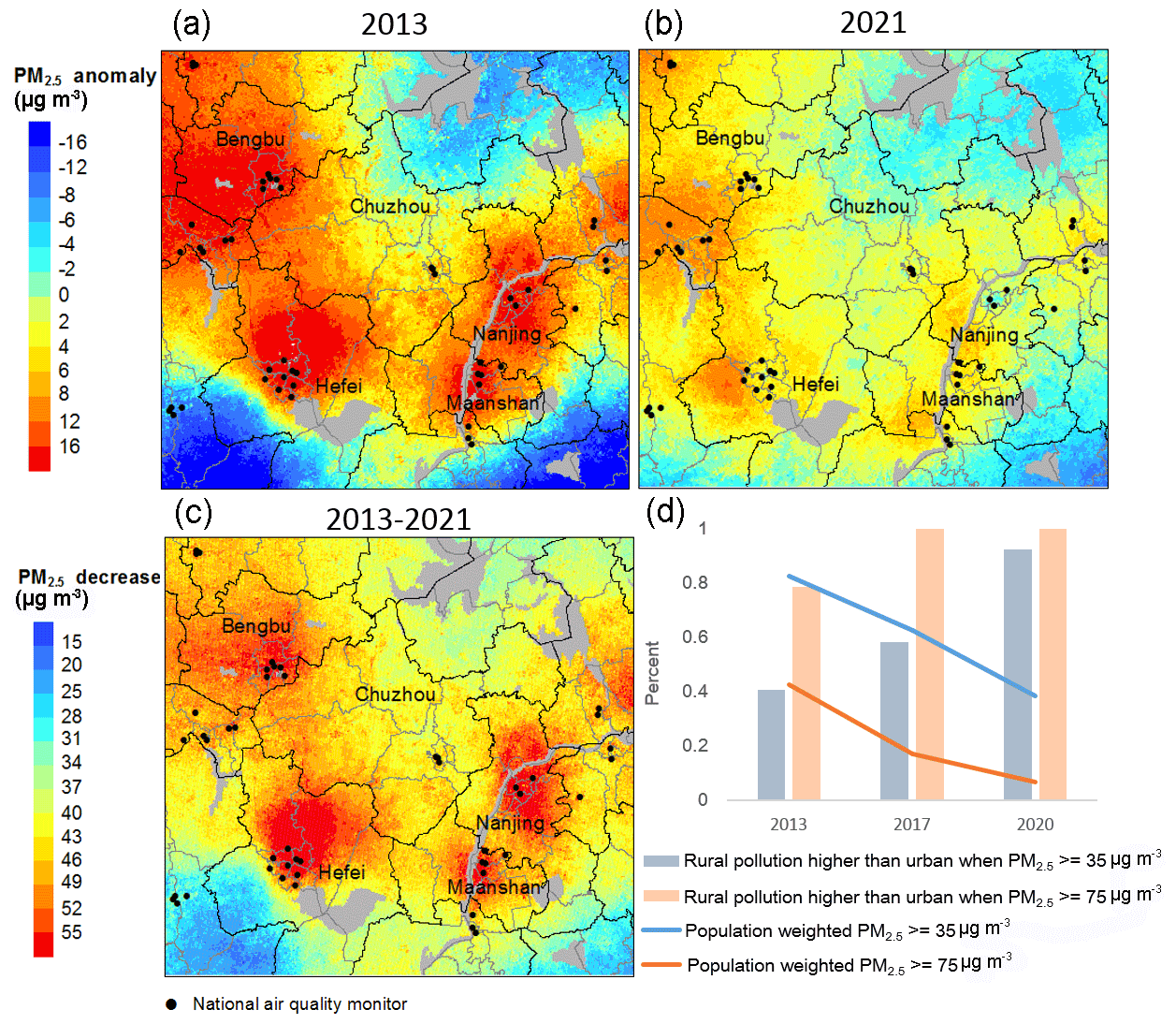
Figure 6The spatial distribution of annual average PM2.5 anomalies, which is the gridded annual average PM2.5 minus the annual regional average PM2.5, in (a) 2013 and (b) 2021 in YRD; (c) the changes in annual average PM2.5 between 2013 and 2021; and (d) the temporal trends in percent of days and counties with rural-county pollution higher than urban-county pollution in this region.
The daily maps showed more short-term local pollution variations. Figure 7 shows one haze event during 18–25 November 2013. Since 18 November, the upper cyclone moved towards the northwest, and the North China Plain was covered by a high-pressure ridge with a continuously strengthening downdraft, leading to a stable atmosphere that was unfavorable for pollution control. From 18–23 November, the pollution kept increasing and trigged the haze event. Then, since 24 November, with the upper-level ridge having moved eastward to the ocean, the North China Plain was affected by the trough with increased vertical upward movement and raised boundary layer height. Both the horizontal and vertical diffusion were improved, and the pollutant concentrations decreased sharply, leading to the end of this haze event.
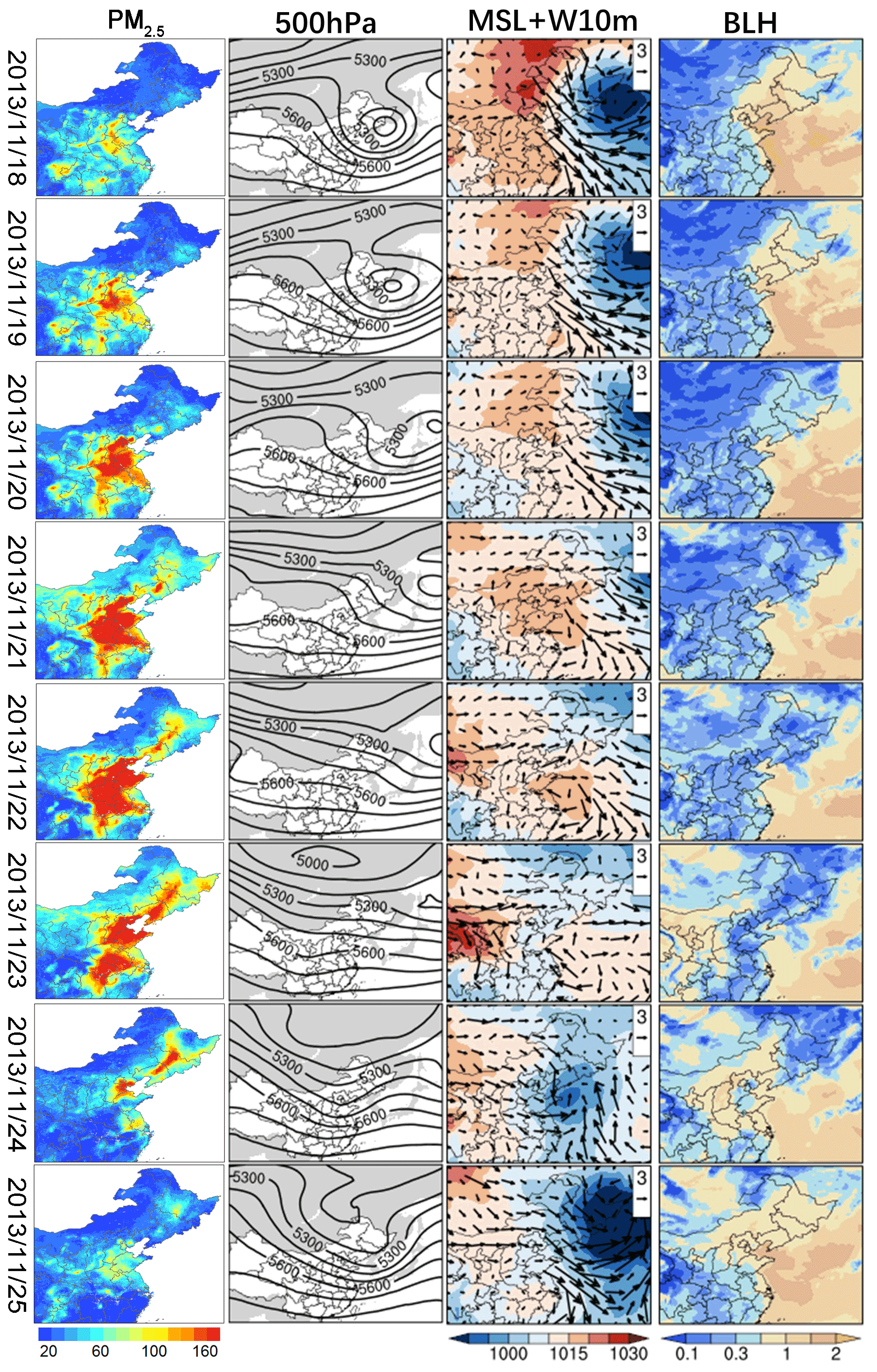
Figure 7Daily PM2.5 and meteorological field distributions during 18–25 November 2013; 500 hPa: the vertical height at which the pressure is 500 hPa; MSL: mean sea level; W10m: wind speed and direction at 10 m; BLH: boundary layer height.
The 1 km resolution pollution map was able to reveal regional characteristics. For example, the impact of local transportation emissions was observed on some days in the populous key regions (Fig. 8). These maps also indicated the importance of including time-varying land use data for air pollution predictions, especially in high-resolution predictions, since the land use characteristics led to noticeable spatial variations in the pollution distribution, as expected. To examine the impact of using temporally mismatched land use data on the retrieved spatial patterns of PM2.5, we used historical land use data (GAIA, NDVI, population and road maps of 2000) to predict the daily PM2.5 distribution over these key regions of the same day. The historical land use data in 2000 led to incorrect spatial characterizations of the PM2.5 distribution in 2015.
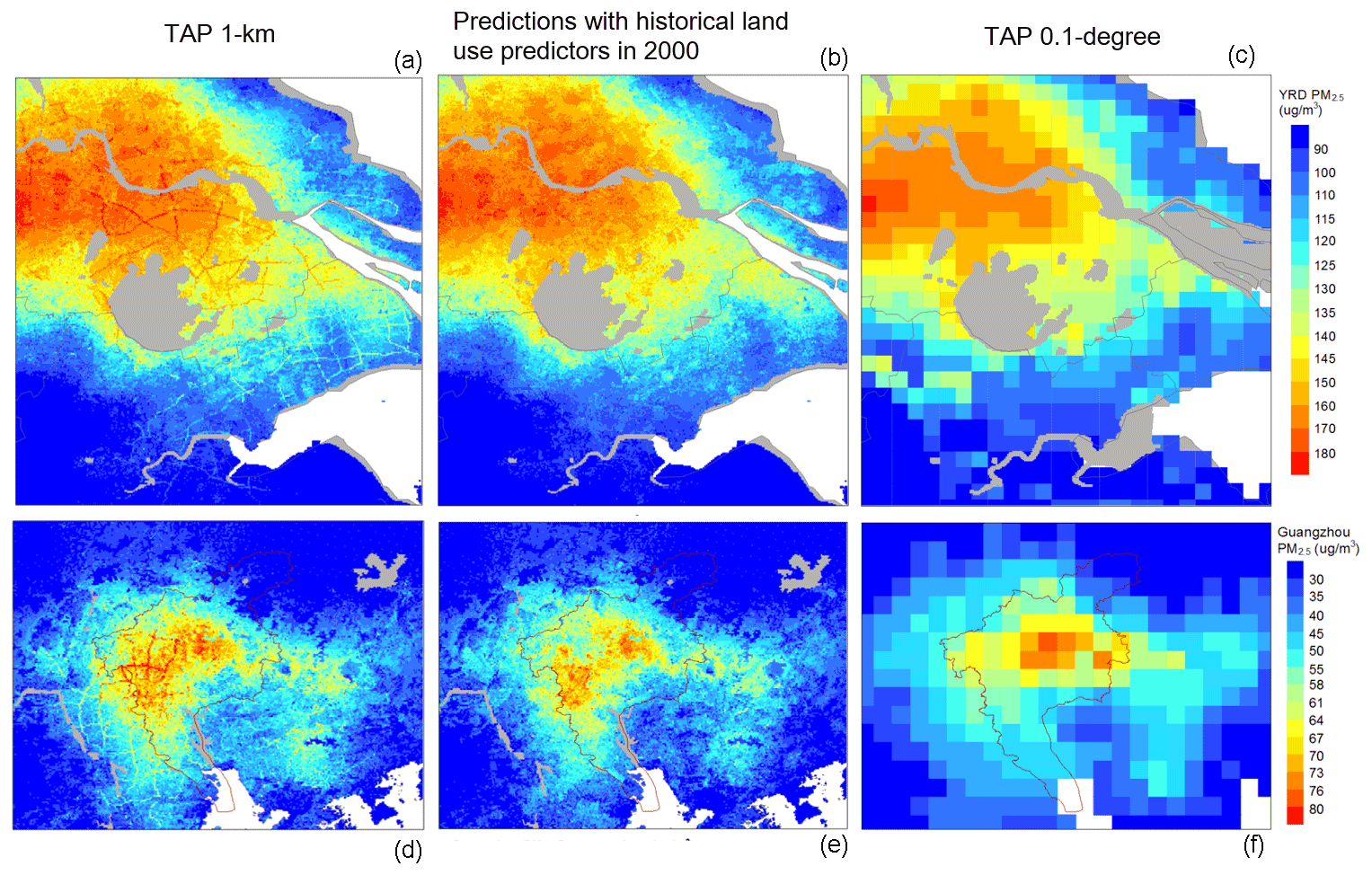
Figure 8The daily PM2.5 distribution in YRD for year 2015, day 25 (a–c) and in PRD for year 2015, day 26 (d–f), with the TAP 1 km PM2.5 predictions (a, d), the prediction with the historical land use predictors of year 2000 (b, e), and the TAP 0.1∘ PM2.5 predictions (c, f).
In this study, we fused the daily 10 km PM2.5 predictions with satellite retrievals and land use data by a random forest model in the TAP framework and produced the open access, daily average PM2.5 distribution at a 1 km resolution with complete coverage from 2000 to the present. To improve the accuracy of the temporal variations in road distributions and other land use data, we processed the annual road map by fusing the OSM data with survey data and processed the annual population distribution by fusing the GPW and the WorldPop data. Our predictions showed an accuracy comparable with previous high-resolution PM2.5 predictions, and our data were advantaged with complete coverage, time-varying land use predictors, and long temporal coverage. Compared to previous TAP products at approximately 10 km resolution, this 1 km resolution PM2.5 data product revealed more local-scale spatial characteristics of the PM2.5 distribution in China.
We conducted various evaluation analyses to optimize the model structure and select the appropriate predictors. When constructing the model structure and selecting the predictors, we not only considered the prediction accuracy but also considered the computation time, data updating frequency, and long-term data availability. For example, we did not include the POI data as predictors, since we have no access to historical POI data in China, and there is no appropriate model to correctly predict POI distributions in previous publications. Including more land use variables will certainly improve the model accuracy; however, since historical data are unavailable, doing so will increase the uncertainty in historical predictions. Similarly, regarding the selected spatial predictors, we constructed temporally continuous data records with various geostatistical methods and improved the data quality by fusing data from various sources to reveal the temporal changes in land use. Including temporally mismatched predictors for PM2.5 prediction leads to misleading spatial patterns, especially in China, with considerable social economic development in the past decades (Fig. 8). Additionally, we did not include any spatial and temporal trends estimated from measurements in the hindcast model that could significantly improve the model performance statistics in the evaluations. The measurement-based spatiotemporal trends did not necessarily reflect the pollution distribution in regions without monitors (Bai et al., 2022a). Since the major aim of data fusing methods is to estimate the PM2.5 variations in regions without monitors, including measurement-based smoothing trends in space and time will hinder the achievement of this goal. Since the predictor processing and modeling of 1 km resolution data is computationally expensive, the predictor selection and model structure selection not only improved model robustness but also allowed us to run a more efficient model daily and support near real-time data updating.
Our model still has several limitations. First, although we improved the model prediction accuracy during high pollution events, we still noticed an underestimation of PM2.5 levels. There could be several reasons for this underestimation. The AOD retrievals tended to misclassify high aerosol loading as cloud cover, leading to missing AOD during haze events. The CTM also hardly predicts high pollution events. The missing satellite retrievals together with the underestimated CTM simulations resulted in the underestimation of pollution levels. We noticed that all the predictors in the model are associated with some uncertainties, and these uncertainties together with the modeling error contributed to the uncertainties of the final PM2.5 predictions. Thus, the quantification of the model uncertainties and their sources could be difficult. Here we conducted various model performance evaluations to illustrate the prediction uncertainties from different angles. We suggested the usage of the out-of-bag evaluation results as an approximate of the uncertainty of PM2.5 prediction after 2013 (Table 1), when the ground PM2.5 monitoring is available, and the usage of the temporal cross-validation results as an approximate of the uncertainty before 2013 (Fig. 4). Second, although we included some regional monitors to increase the density of monitors for model training, the number of monitors in western China is still insufficient. Thus, the uncertainty of PM2.5 predictions in these regions lacking data could be larger than in the regions with dense data. However, the distribution of monitors in China basically followed the population distribution in which populous regions hold more monitors; thus, the key regions of air pollution control have more training data and high-quality predictions, benefiting air quality management and environmental health studies in the future.
In this study, we constructed a high-resolution PM2.5 prediction model fused with MAIAC satellite aerosol optical depth retrievals, 10 km TAP PM2.5 data, and land use variables including road maps, population distribution, artificial impervious area, and vegetation index. To describe the significant temporal variations in land use characteristics resulting from the economic development in China, we constructed spatiotemporally continuous land use predictors through statistical and spatial modeling. Optimization of model structure and predictors was conducted with various performance evaluation methods to balance the model performance and computing cost. We revealed changes in local-scale spatial patterns of PM2.5 associated with pollution control measures. For example, pollution hotspots transferred from city centers to rural regions with limited air quality monitoring. We showed that the land use data affected the predicted spatial distribution of PM2.5 and that the usage of updated spatial data is beneficial. The gridded 1 km resolution PM2.5 predictions can be openly accessed through the TAP website (http://tapdata.org.cn/, last access: 3 October 2022).
The 1 km resolution PM2.5 predictions are available (login required) on the TAP website (http://tapdata.org.cn/PM2.5-1km-data-download, last access: 3 October 2022, Tsinghua University, 2022).
The supplement related to this article is available online at: https://doi.org/10.5194/acp-22-13229-2022-supplement.
QX, GG and QZ designed the study. SL ran the CMAQ simulations. LJ conducted the analysis on the meteorological effects on the haze events. XM collected and provided the road maps. QX trained the PM2.5 prediction models and conducted the spatiotemporal analyses. QX prepared the manuscript with contributions from all co-authors.
The contact author has declared that none of the authors has any competing interests.
Publisher's note: Copernicus Publications remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This research has been supported by the National Natural Science Foundation of China (grant nos. 42007189, 42005135, and 41921005).
This paper was edited by Qi Chen and reviewed by two anonymous referees.
Bai, K., Li, K., Guo, J., and Chang, N.-B.: Multiscale and multisource data fusion for full-coverage PM2.5 concentration mapping: Can spatial pattern recognition come with modeling accuracy?, ISPRS J. Photogramm., 184, 31–44, https://doi.org/10.1016/j.isprsjprs.2021.12.002, 2022a.
Bai, K., Li, K., Ma, M., Li, K., Li, Z., Guo, J., Chang, N.-B., Tan, Z., and Han, D.: LGHAP: the Long-term Gap-free High-resolution Air Pollutant concentration dataset, derived via tensor-flow-based multimodal data fusion, Earth Syst. Sci. Data, 14, 907–927, https://doi.org/10.5194/essd-14-907-2022, 2022b.
Bai, Z., Wang, J., Wang, M., Gao, M., and Sun, J.: Accuracy assessment of multi-source gridded population distribution datasets in China, Sustainability, 10, 1363, https://doi.org/10.3390/su10051363, 2018.
Barrington-Leigh, C., and Millard-Ball, A.: The world’s user-generated road map is more than 80 % complete, PLoS One, 12, e0180698, https://doi.org/10.1371/journal.pone.0180698, 2017.
Dobson, J. E., Bright, E. A., Coleman, P. R., Durfee, R. C., and Worley, B. A.: LandScan: a global population database for estimating populations at risk, Photogramm. Eng. Rem. S., 66, 849–857, 2000.
Doxsey-Whitfield, E., MacManus, K., Adamo, S. B., Pistolesi, L., Squires, J., Borkovska, O., and Baptista, S. R.: Taking advantage of the improved availability of census data: a first look at the gridded population of the world, version 4, Papers in Applied Geography, 1, 226–234, https://doi.org/10.1080/23754931.2015.1014272, 2015.
Geng, G., Xiao, Q., Liu, S., Liu, X., Cheng, J., Zheng, Y., Xue, T., Tong, D., Zheng, B., Peng, Y., Huang, X., He, K., and Zhang, Q.: Tracking air pollution in China: near real-time PM2.5 retrievals from multisource data fusion, Environ. Sci. Technol., 55, 12106–12115, https://doi.org/10.1021/acs.est.1c01863, 2021.
Goldberg, D. L., Gupta, P., Wang, K., Jena, C., Zhang, Y., Lu, Z., and Streets, D. G.: Using gap-filled MAIAC AOD and WRF-Chem to estimate daily PM2.5 concentrations at 1 km resolution in the Eastern United States, Atmos. Environ., 199, 443–452, https://doi.org/10.1016/j.atmosenv.2018.11.049, 2019.
Haklay, M.: How good is volunteered geographical information? A comparative study of OpenStreetMap and Ordnance survey datasets, Environ. Plann. B, 37, 682–703, https://doi.org/10.1068/b35097, 2010.
He, Q. Q. and Huang, B.: Satellite-based mapping of daily high-resolution ground PM2.5 in China via space-time regression modeling, Remote. Sens. Environ., 206, 72–83, https://doi.org/10.1016/j.rse.2017.12.018, 2018.
Hu, H. D., Hu, Z. Y., Zhong, K. W., Xu, J. H., Zhang, F. F., Zhao, Y., and Wu, P. H.: Satellite-based high-resolution mapping of ground-level PM2.5 concentrations over East China using a spatiotemporal regression kriging model, Sci. Total. Environ., 672, 479–490, https://doi.org/10.1016/j.scitotenv.2019.03.480, 2019.
Huang, C., Hu, J., Xue, T., Xu, H., and Wang, M.: High-Resolution spatiotemporal modeling for ambient PM2.5 exposure assessment in China from 2013 to 2019, Environ. Sci. Technol, 55, 2152–2162, https://doi.org/10.1021/acs.est.0c05815, 2021.
Kloog, I., Sorek-Hamer, M., Lyapustin, A., Coull, B., Wang, Y., Just, A. C., Schwartz, J., and Broday, D. M.: Estimating daily PM2.5 and PM10 across the complex geo-climate region of Israel using MAIAC satellite-based AOD data, Atmos. Environ., 122, 409-416, https://doi.org/10.1016/j.atmosenv.2015.10.004, 2015.
Lyapustin, A.: MODIS Multi-Angle Implementation of Atmospheric Correction (MAIAC) data user's guide, https://lpdaac.usgs.gov/documents/110/MCD19_User_Guide_V6.pdf (last access: 3 October 2022), 2018.
Lyapustin, A., Martonchik, J., Wang, Y., Laszlo, I., and Korkin, S.: Multiangle implementation of atmospheric correction (MAIAC): 1. Radiative transfer basis and look-up tables, J. Geophys. Res., 116, D03210, https://doi.org/10.1029/2010JD014985, 2011a.
Lyapustin, A., Wang, Y., Laszlo, I., Kahn, R., Korkin, S., Remer, L., Levy, R., and Reid, J.: Multiangle implementation of atmospheric correction (MAIAC): 2. Aerosol algorithm, J. Geophys. Res., 116, D03211, https://doi.org/10.1029/2010JD014986, 2011b.
Ma, R., Ban, J., Wang, Q., Zhang, Y., Yang, Y., Li, S., Shi, W., Zhou, Z., Zang, J., and Li, T.: Full-coverage 1 km daily ambient PM2.5 and O3 concentrations of China in 2005–2017 based on a multi-variable random forest model, Earth Syst. Sci. Data, 14, 943–954, https://doi.org/10.5194/essd-14-943-2022, 2022.
Meijer, J. R., Huijbregts, M. A. J., Schotten, K. C. G. J., and Schipper, A. M.: Global patterns of current and future road infrastructure, Environ. Res. Lett., 13, 064006, https://doi.org/10.1088/1748-9326/aabd42, 2018.
Reed, F. J., Gaughan, A. E., Stevens, F. R., Yetman, G., Sorichetta, A., and Tatem, A. J.: Gridded population maps informed by different built settlement products, Data, 3, 33, https://doi.org/10.3390/data3030033, 2018.
Tsinghua University: China 1-km PM2.5, TAP [data set], http://tapdata.org.cn/PM2.5-1km-data-download, last access: 3 October 2022.
Wang, X. M., Li, X., and Ma, M.-G.: Advance and case analysis in population spatial distribution based on remote sensing and GIS, Remote Sensing Technology and Application, 19, 320–327, 2011.
Wardrop, N. A., Jochem, W. C., Bird, T. J., Chamberlain, H. R., Clarke, D., Kerr, D., Bengtsson, L., Juran, S., Seaman, V., and Tatem, A. J.: Spatially disaggregated population estimates in the absence of national population and housing census data, P. Natl. Acad. Sci. USA, 115, 3529–3537, https://doi.org/10.1073/pnas.1715305115, 2018.
Wei, J., Huang, W., Li, Z., Xue, W., Peng, Y., Sun, L., and Cribb, M.: Estimating 1 km-resolution PM2.5 concentrations across China using the space-time random forest approach, Remote. Sens. Environ., 231, 111221, https://doi.org/10.1016/j.rse.2019.111221, 2019.
Wei, J., Li, Z., Cribb, M., Huang, W., Xue, W., Sun, L., Guo, J., Peng, Y., Li, J., Lyapustin, A., Liu, L., Wu, H., and Song, Y.: Improved 1 km resolution PM2.5 estimates across China using enhanced space–time extremely randomized trees, Atmos. Chem. Phys., 20, 3273–3289, https://doi.org/10.5194/acp-20-3273-2020, 2020.
Wei, J., Li, Z., Lyapustin, A., Sun, L., Peng, Y., Xue, W., Su, T., and Cribb, M.: Reconstructing 1 km-resolution high-quality PM2.5 data records from 2000 to 2018 in China: spatiotemporal variations and policy implications, Remote. Sens. Environ., 252, 112136, https://doi.org/10.1016/j.rse.2020.112136, 2021.
Xiao, Q., Wang, Y., Chang, H. H., Meng, X., Geng, G., Lyapustin, A., and Liu, Y.: Full-coverage high-resolution daily PM2.5 estimation using MAIAC AOD in the Yangtze River Delta of China, Remote. Sens. Environ., 199, 437–446, https://doi.org/10.1016/j.rse.2017.07.023, 2017.
Xiao, Q., Geng, G., Liang, F., Wang, X., Lv, Z., Lei, Y., Huang, X., Zhang, Q., Liu, Y., and He, K.: Changes in spatial patterns of PM2.5 pollution in China 2000–2018: Impact of clean air policies, Environ. Int., 141, 105776, https://doi.org/10.1016/j.envint.2020.105776, 2020.
Xiao, Q., Geng, G., Cheng, J., Liang, F., Li, R., Meng, X., Xue, T., Huang, X., Kan, H., Zhang, Q., and He, K.: Evaluation of gap-filling approaches in satellite-based daily PM2.5 prediction models, Atmos. Environ., 244, 117921, https://doi.org/10.1016/j.atmosenv.2020.117921, 2021a.
Xiao, Q., Geng, G., Xue, T., Liu, S., Cai, C., He, K., and Zhang, Q.: Tracking PM2.5 and O3 Pollution and the Related Health Burden in China 2013–2020, Environ. Sci. Technol., https://doi.org/10.1021/acs.est.1c04548, 2021b.
Xiao, Q., Zheng, Y., Geng, G., Chen, C., Huang, X., Che, H., Zhang, X., He, K., and Zhang, Q.: Separating emission and meteorological contributions to long-term PM2.5 trends over eastern China during 2000–2018, Atmos. Chem. Phys., 21, 9475–9496, https://doi.org/10.5194/acp-21-9475-2021, 2021c.
Xie, Y. Y., Wang, Y. X., Zhang, K., Dong, W. H., Lv, B. L., and Bai, Y. Q.: Daily Estimation of Ground-Level PM2.5 Concentrations over Beijing Using 3 km Resolution MODIS AOD, Environ. Sci. Technol., 49, 12280–12288, https://doi.org/10.1021/acs.est.5b01413, 2015.
Zhang, T., Zhu, Z., Gong, W., Zhu, Z., Sun, K., Wang, L., Huang, Y., Mao, F., Shen, H., Li, Z., and Xu, K.: Estimation of ultrahigh resolution PM2.5 concentrations in urban areas using 160 m Gaofen-1 AOD retrievals, Remote. Sens. Environ., 216, 91–104, https://doi.org/10.1016/j.rse.2018.06.030, 2018.
Zhang, Y., Li, X., Wang, A., Bao, T., and Tian, S.: Density and diversity of OpenStreetMap road networks in China, Journal of Urban Management, 4, 135–146, https://doi.org/10.1016/j.jum.2015.10.001, 2015.